Documentation Index
Fetch the complete documentation index at: https://mintlify.com/QwenLM/Qwen3-VL/llms.txt
Use this file to discover all available pages before exploring further.
Overview
Qwen3-VL has been extensively evaluated on a wide range of benchmarks to demonstrate its capabilities in both visual understanding and text processing. Below are the comprehensive benchmark results for all model variants.Visual Tasks Performance
Large Models (235B & 30B MoE)
Instruct Models - Visual Tasks
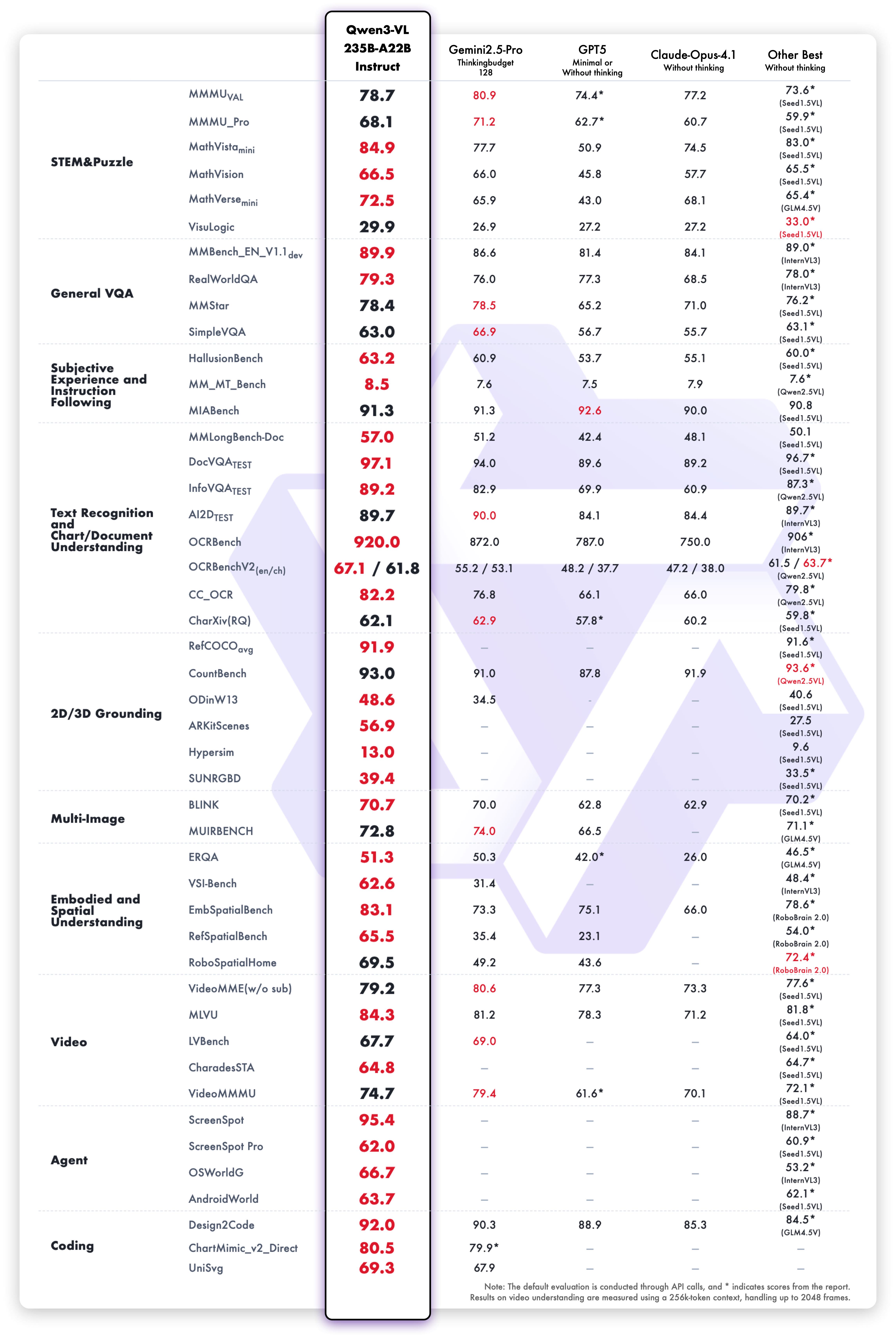 Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-30B-A3B-Instruct demonstrate state-of-the-art performance across visual benchmarks.
Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-30B-A3B-Instruct demonstrate state-of-the-art performance across visual benchmarks.
Thinking Models - Visual Tasks
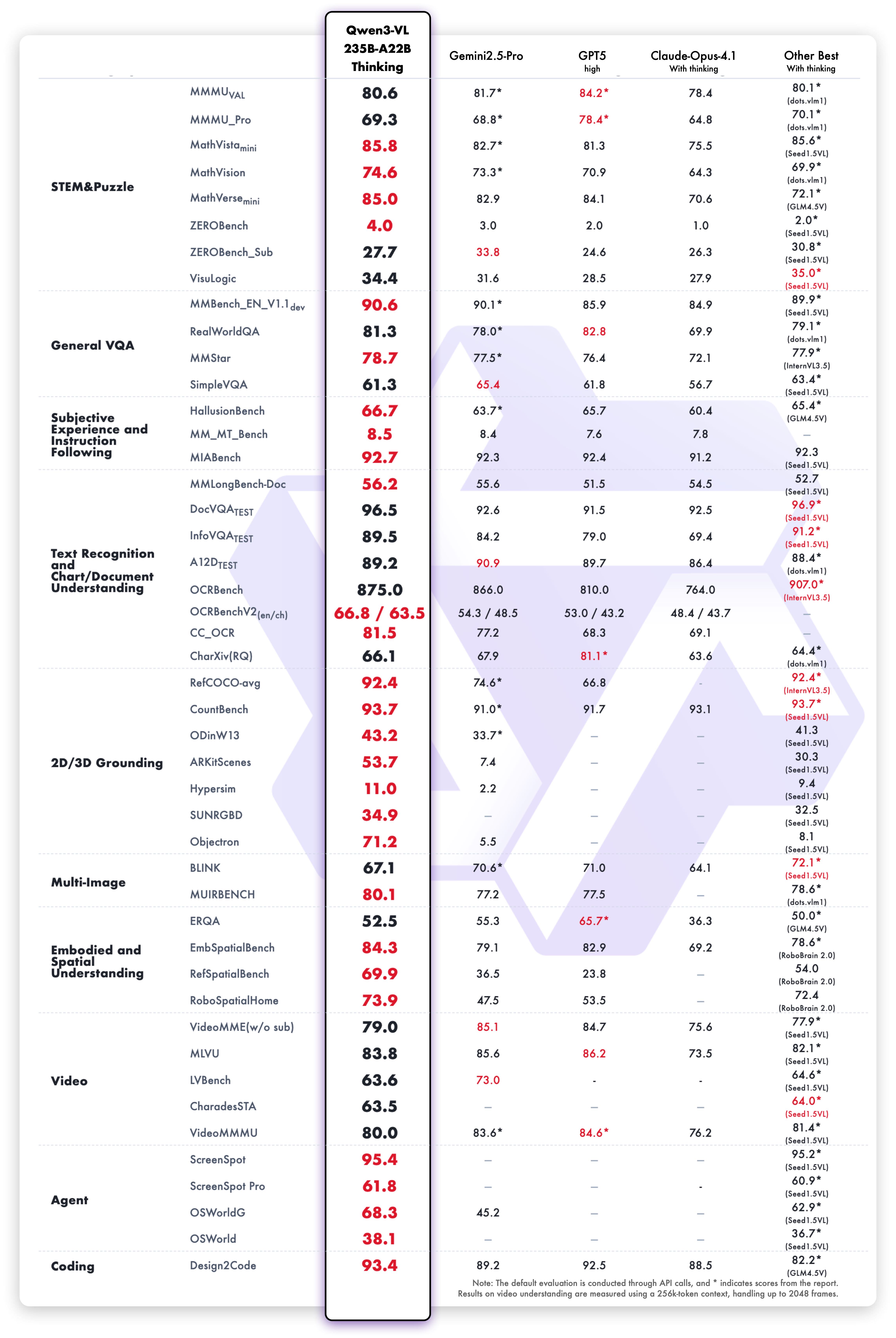 Qwen3-VL-235B-A22B-Thinking and Qwen3-VL-30B-A3B-Thinking show enhanced reasoning capabilities on complex visual tasks.
Qwen3-VL-235B-A22B-Thinking and Qwen3-VL-30B-A3B-Thinking show enhanced reasoning capabilities on complex visual tasks.
MoE Models Comparison
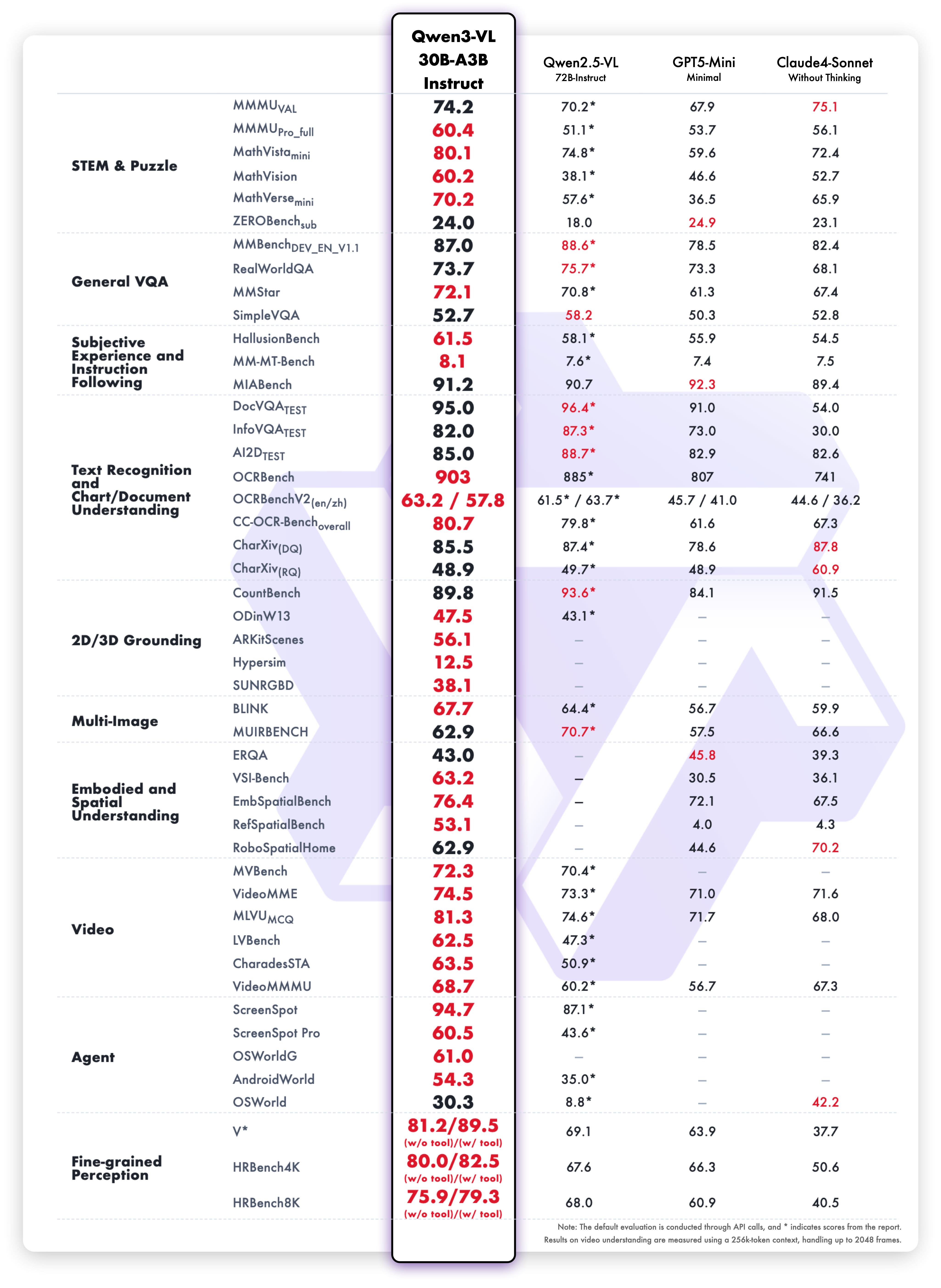
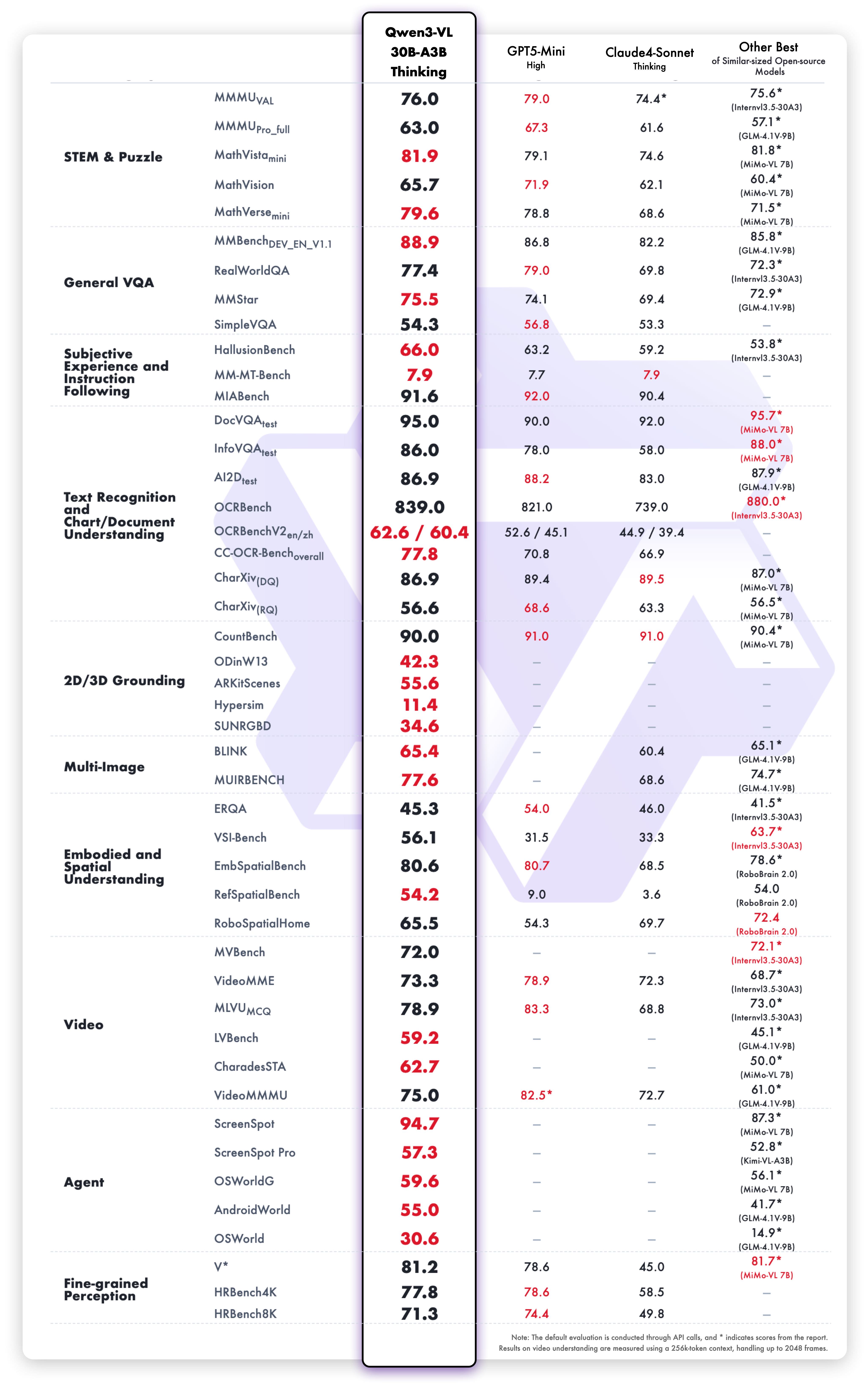
Smaller Models (2B-32B Dense)
2B & 32B Models - Visual Tasks
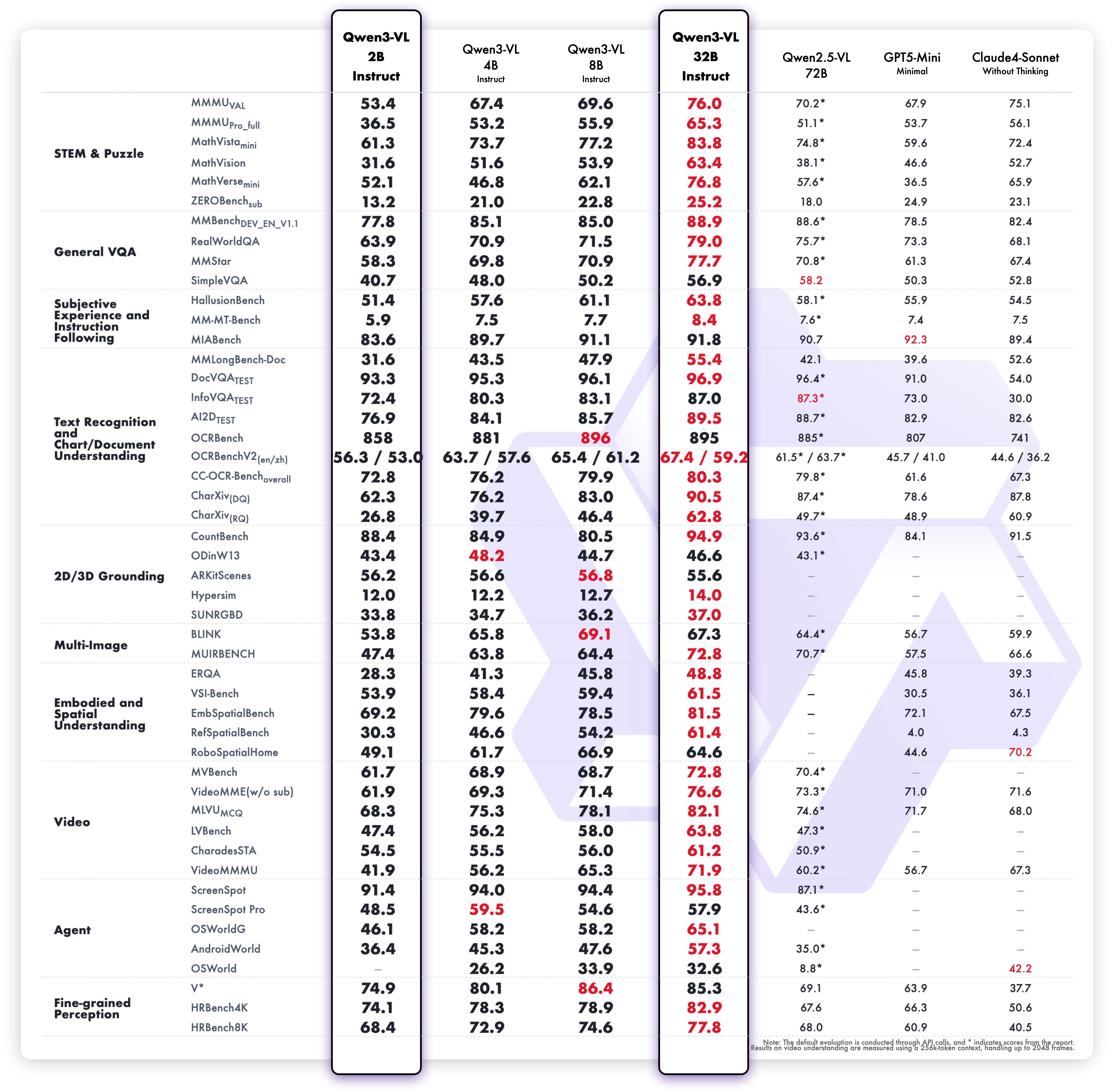
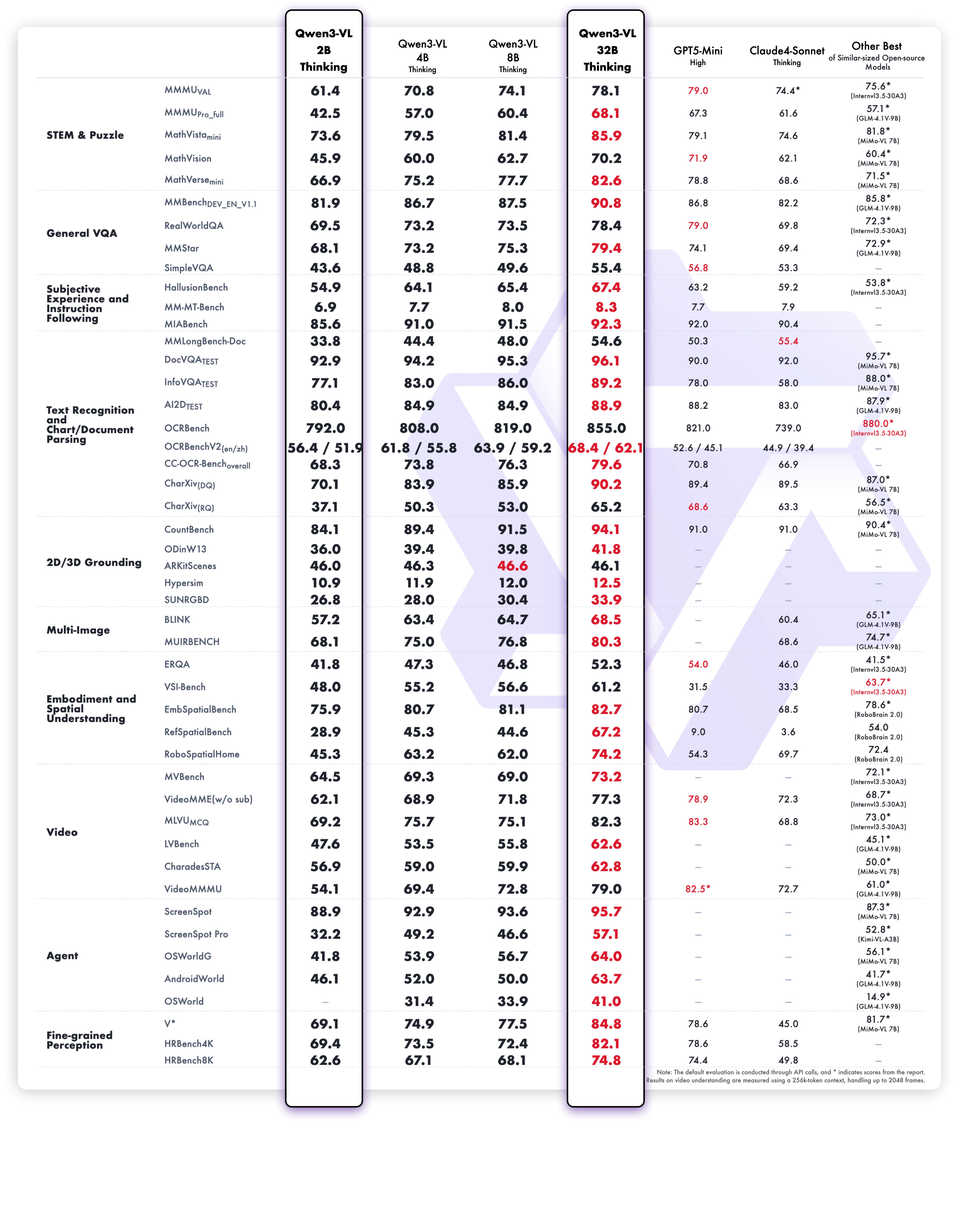
Text-Centric Tasks Performance
Large Models (235B & 30B MoE)
Instruct Models - Text Tasks
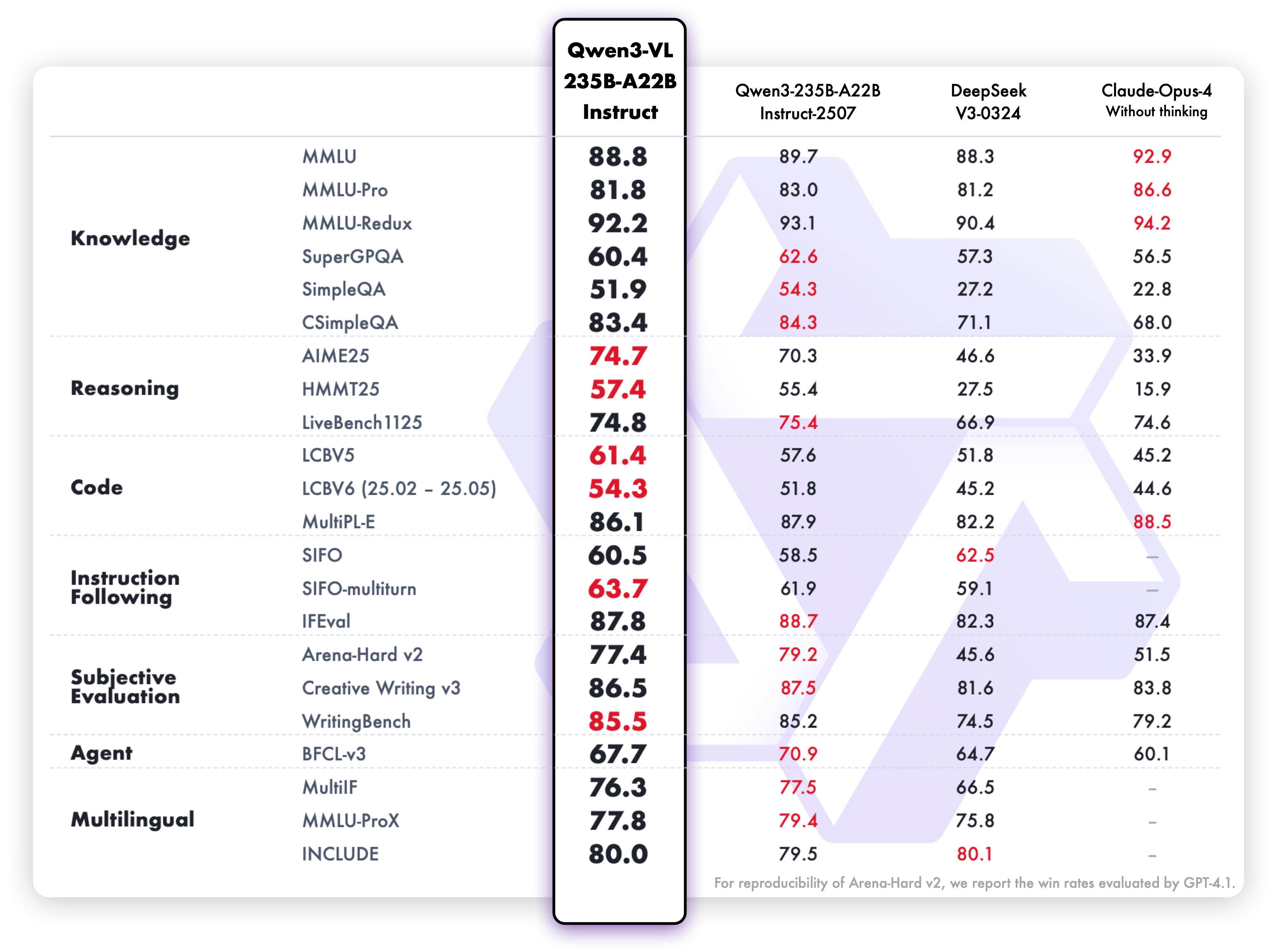 Qwen3-VL demonstrates text understanding on par with pure LLMs, showing seamless text-vision fusion.
Qwen3-VL demonstrates text understanding on par with pure LLMs, showing seamless text-vision fusion.
Thinking Models - Text Tasks
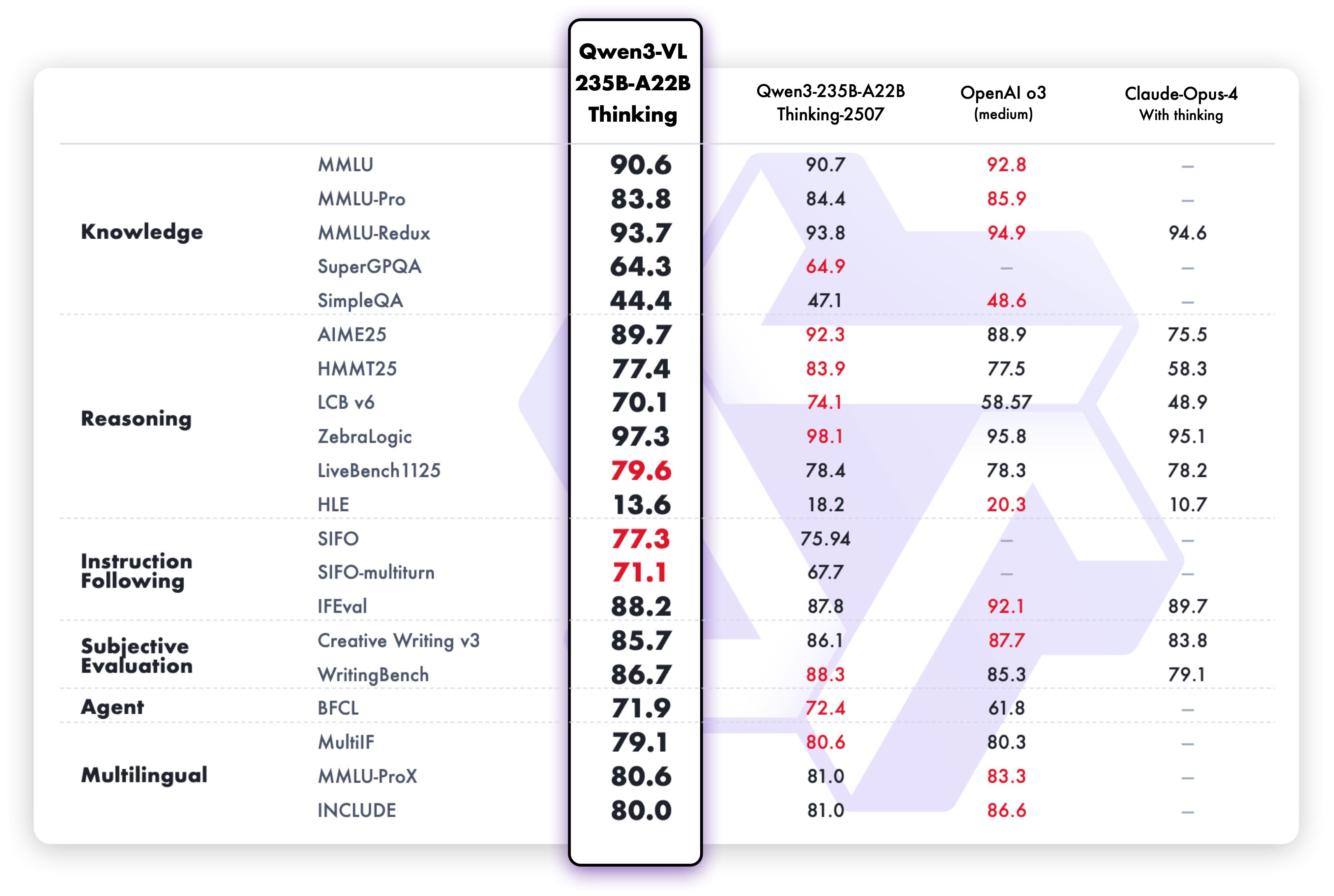 Thinking editions show enhanced performance on reasoning-heavy text tasks.
Thinking editions show enhanced performance on reasoning-heavy text tasks.
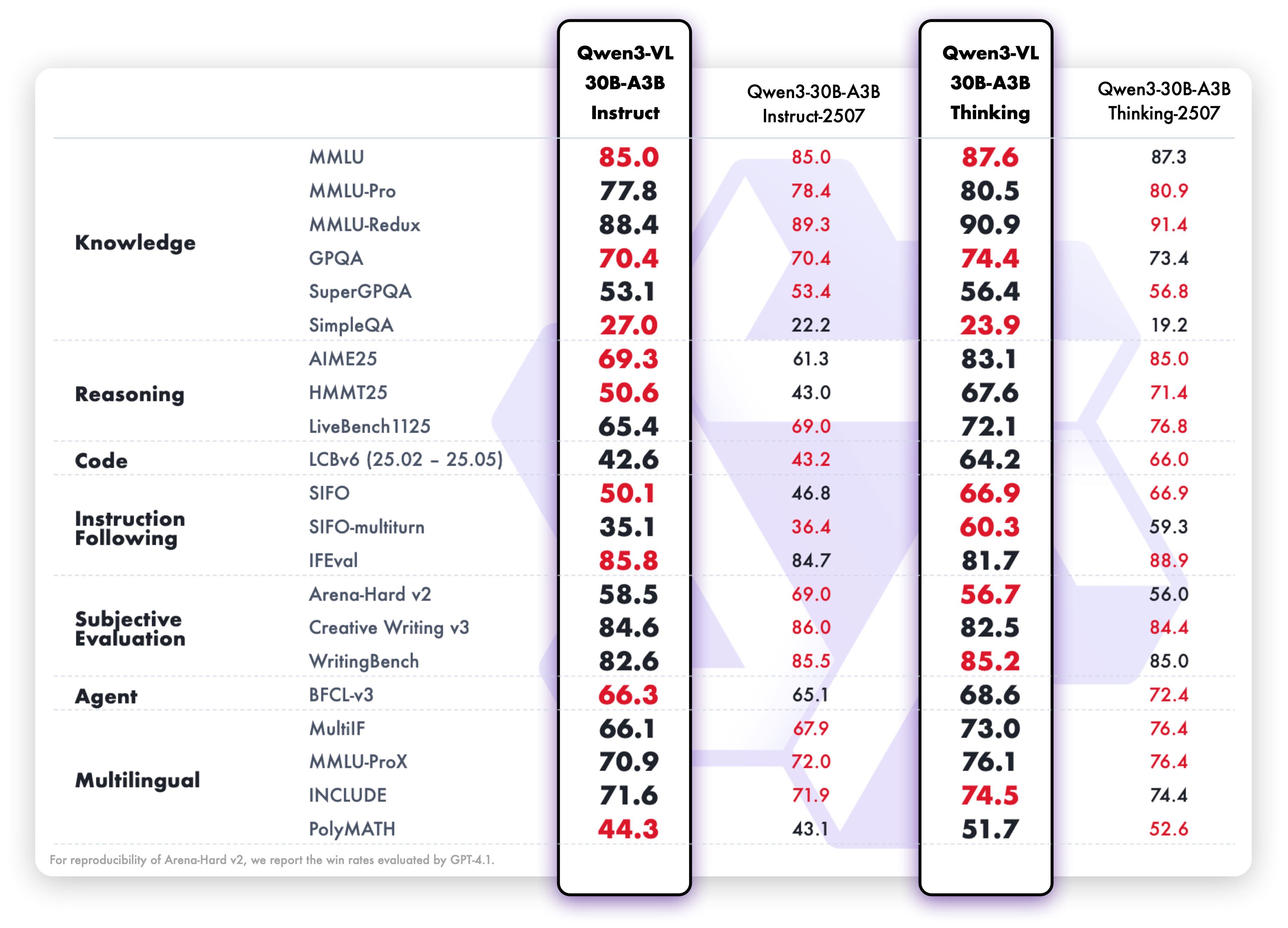
MoE Model - Text Tasks
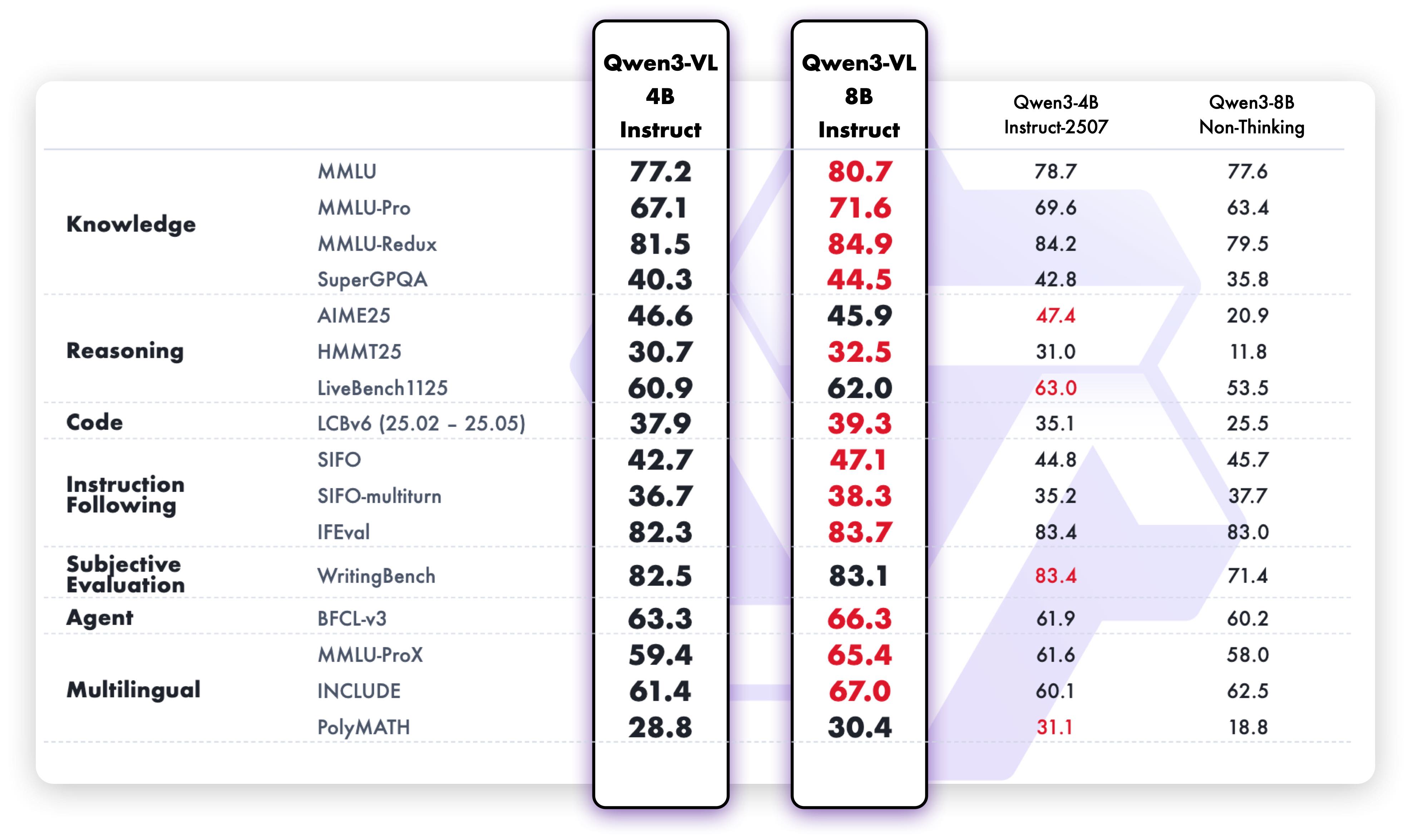
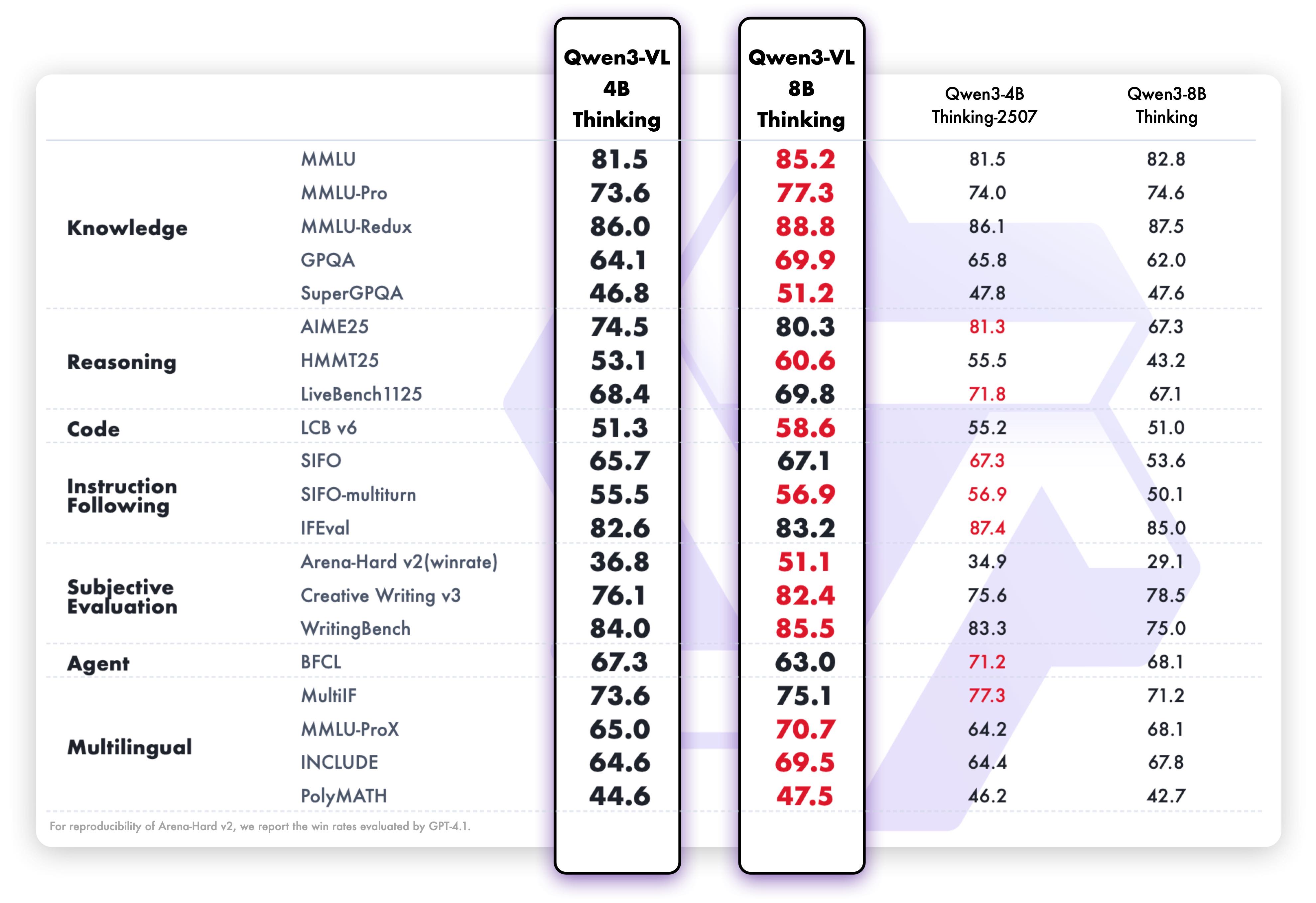
Smaller Models (4B & 8B Dense)
4B & 8B Models - Text Tasks
Key Capabilities
Visual Understanding
- Image Recognition: State-of-the-art performance on standard vision benchmarks
- OCR: Support for 32 languages with robustness to challenging conditions
- Document Parsing: Advanced layout understanding and structure extraction
- Object Grounding: Precise 2D and 3D object localization
- Video Understanding: Long-form video comprehension with temporal reasoning
Text Processing
- Pure Text Tasks: Performance comparable to dedicated LLMs
- Multimodal Reasoning: Seamless integration of visual and textual information
- STEM/Math: Enhanced reasoning capabilities, especially in Thinking editions
- Multilingual: Strong performance across multiple languages
Specialized Capabilities
- Spatial Understanding: Advanced 3D reasoning and spatial relationships
- Coding: Visual coding from screenshots to HTML/CSS/JavaScript
- Agent Tasks: GUI interaction and tool use
- Long Context: Native 256K tokens, expandable to 1M
Evaluation Settings
To ensure reproducibility, we provide our official evaluation configuration:Inference & Evaluation
- Inference Runtime: vLLM
- Evaluation Frameworks:
Generation Hyperparameters
Instruct Models
Thinking Models
Notes on Evaluation
- For certain benchmarks, evaluation prompts were slightly modified for better performance
- Some benchmarks are internally constructed; reproduction code will be released
- Detailed methodology will be documented in the technical report
Benchmark Categories
Visual Tasks Evaluated
- General vision understanding
- OCR and document analysis
- Object detection and grounding
- Video question answering
- Spatial reasoning
- Visual coding
- Agent tasks (GUI interaction)
Text-Centric Tasks Evaluated
- Natural language understanding
- Mathematical reasoning
- Code understanding and generation
- Logical reasoning
- Common sense reasoning
- Multilingual comprehension
Performance Highlights
Qwen3-VL-235B-A22B
- Best-in-class performance across most benchmarks
- State-of-the-art visual reasoning
- Comparable to pure LLMs on text tasks
Qwen3-VL-30B-A3B
- Excellent performance-to-cost ratio
- MoE architecture for efficient inference
- Strong across both visual and text tasks
Qwen3-VL-2B to 32B
- Scalable performance across model sizes
- 2B suitable for edge deployment
- 32B competitive with larger models
- Thinking editions show consistent improvements
Related Resources
- Model Cards - Download links for all models
- Quickstart - Get started with inference
- Technical Paper - In-depth technical details