
Documentation Index
Fetch the complete documentation index at: https://mintlify.com/mlfoundations/open_clip/llms.txt
Use this file to discover all available pages before exploring further.
Contrastive Learning in CLIP
Contrastive learning is the training methodology that enables CLIP to learn aligned visual and semantic representations. The key insight: maximize agreement between matched image-text pairs while minimizing agreement between mismatched pairs.Core Concept
Given a batch of N (image, text) pairs:- Encode all images → N image embeddings
- Encode all texts → N text embeddings
- Compute N×N similarity matrix
- Train to maximize diagonal (correct pairs) and minimize off-diagonal (incorrect pairs)
Symmetric Loss: CLIP computes loss from both image→text and text→image directions, ensuring bidirectional alignment.
The Contrastive Loss Function
OpenCLIP implements the contrastive loss insrc/open_clip/loss.py. The core loss is a symmetric cross-entropy loss over the similarity matrix.
Implementation
Fromsrc/open_clip/loss.py:68-155:
Logits Computation
Fromsrc/open_clip/loss.py:104-130:
Mathematical Formulation
Given normalized embeddings I (images) and T (texts):Similarity Matrix
- τ (tau) =
logit_scale.exp()- learnable temperature parameter - S[i,j] = scaled cosine similarity between i-th image and j-th text
Loss Function
Visual-Semantic Embedding Space
Contrastive learning creates a joint embedding space where:Positive Pairs (Matching)
- Image of “a dog playing fetch” ↔ Text “a dog playing fetch”
- Model learns to embed these close together
- High cosine similarity (→ 1.0)
Negative Pairs (Mismatched)
- Image of “a dog playing fetch” ↔ Text “a cat sleeping”
- Model learns to embed these far apart
- Low cosine similarity (→ 0.0 or negative)
Emergent Properties
Through large-scale contrastive training:- Semantic clustering - Similar concepts cluster together
- Cross-modal alignment - “dog” (text) aligns with dog images
- Compositional understanding - Model learns objects, actions, attributes
- Zero-shot transfer - Embeddings generalize to unseen concepts
Training Objective and Batch Construction
In-Batch Negatives
CLIP uses an efficient strategy: in-batch negatives- Batch size N creates N positive pairs
- Each pair has (N-1) negative examples from other samples
- Total comparisons: N² (N positive + N(N-1) negative)
Batch Construction Example
Given batch size N=4:Ground Truth Labels
Fromsrc/open_clip/loss.py:91-102:
[0, 1, 2, ..., N-1] - each sample matches its corresponding index.
Advanced Training Techniques
Local Loss
For distributed training, compute loss locally on each GPU to save memory:Gather with Gradient
Enable gradient flow during all-gather operation:SigLIP Loss (Alternative)
OpenCLIP also implements SigLIP loss fromsrc/open_clip/loss.py:330-464:
- Better scaling to very large batches
- No softmax normalization overhead
- Independent per-pair loss computation
Training Configuration
Example training with contrastive loss:Key Hyperparameters
- Batch size: Larger = more negatives = better training (256-32K typical)
- Learning rate: 5e-4 to 1e-3 typical for CLIP
- Warmup: Gradual learning rate increase (2000-10000 steps)
- Temperature (τ): Learned, initialized to ~2.66
Loss Curves
During training, monitor:- Contrastive loss - Should decrease steadily
- Accuracy - Top-1/Top-5 on diagonal predictions
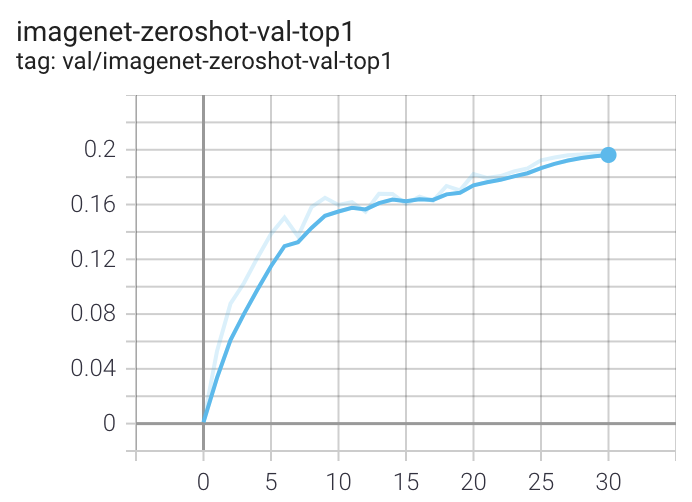
- Zero-shot metrics - Periodic ImageNet zero-shot evaluation
When run on a machine with 8 GPUs the command should produce the following training curve for Conceptual Captions
Reference Implementation
Key files:src/open_clip/loss.py- ClipLoss, SigLipLoss, CoCaLoss implementationssrc/open_clip/model.py:265-480- CLIP model with forward passsrc/open_clip_train/train.py- Training loop
Related Concepts
CLIP Overview
High-level architecture and design principles
Zero-Shot Classification
How contrastive embeddings enable zero-shot inference
Further Reading
- Original CLIP Paper: Learning Transferable Visual Models From Natural Language Supervision
- SigLIP Paper: Sigmoid Loss for Language Image Pre-Training
- OpenCLIP Scaling Laws: Reproducible scaling laws for contrastive language-image learning