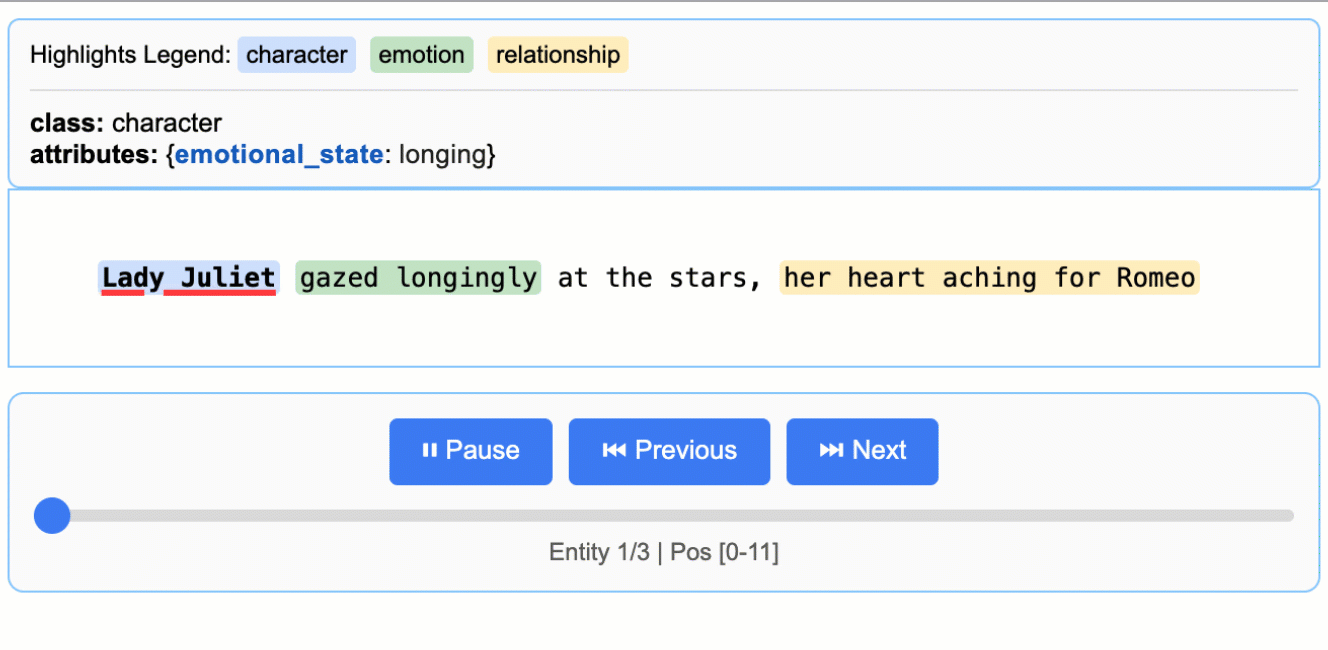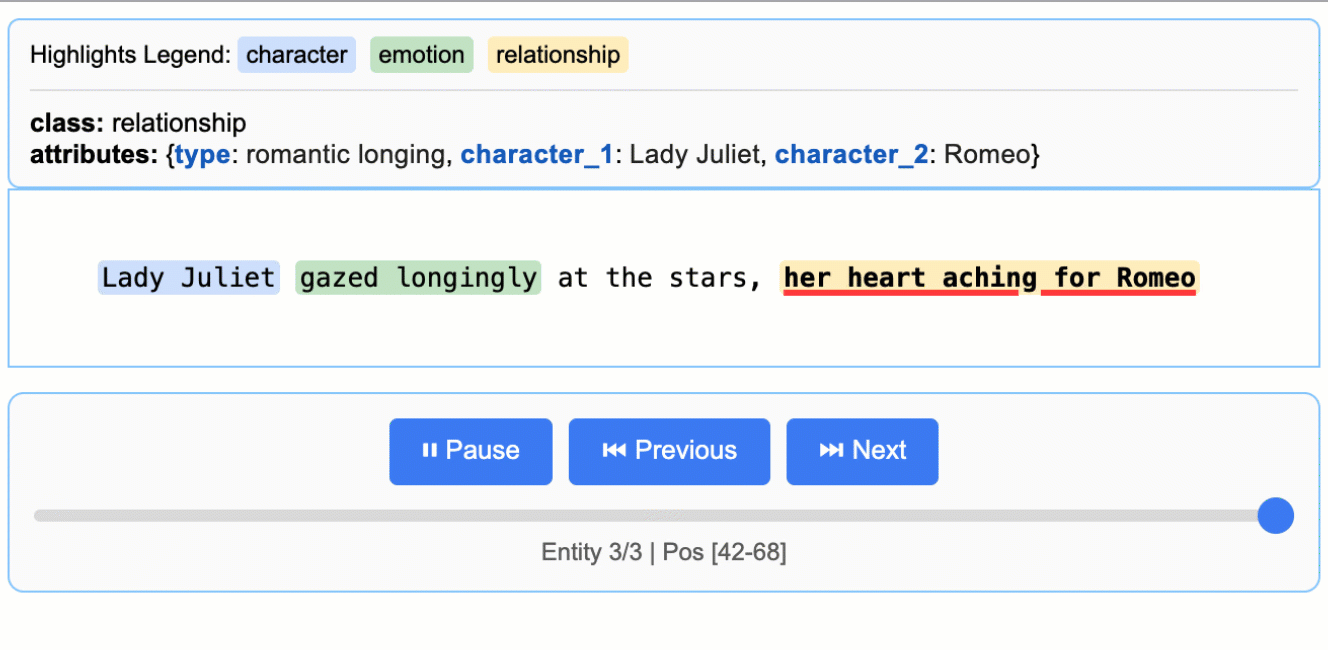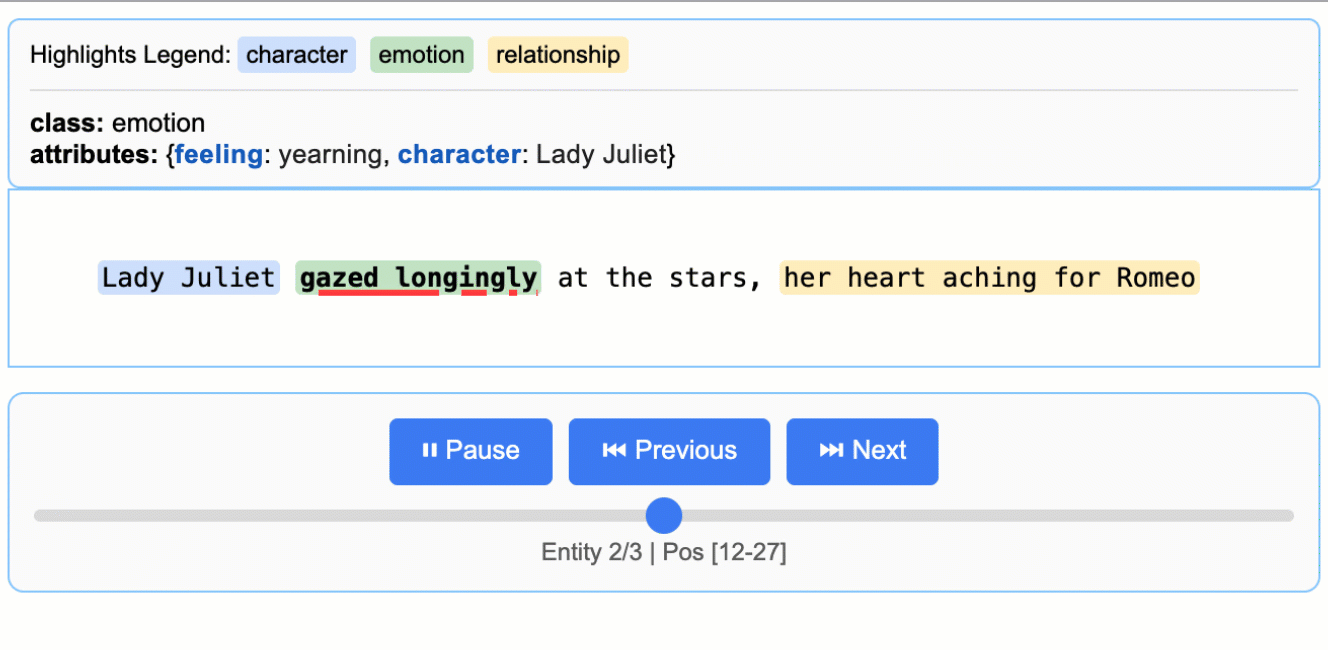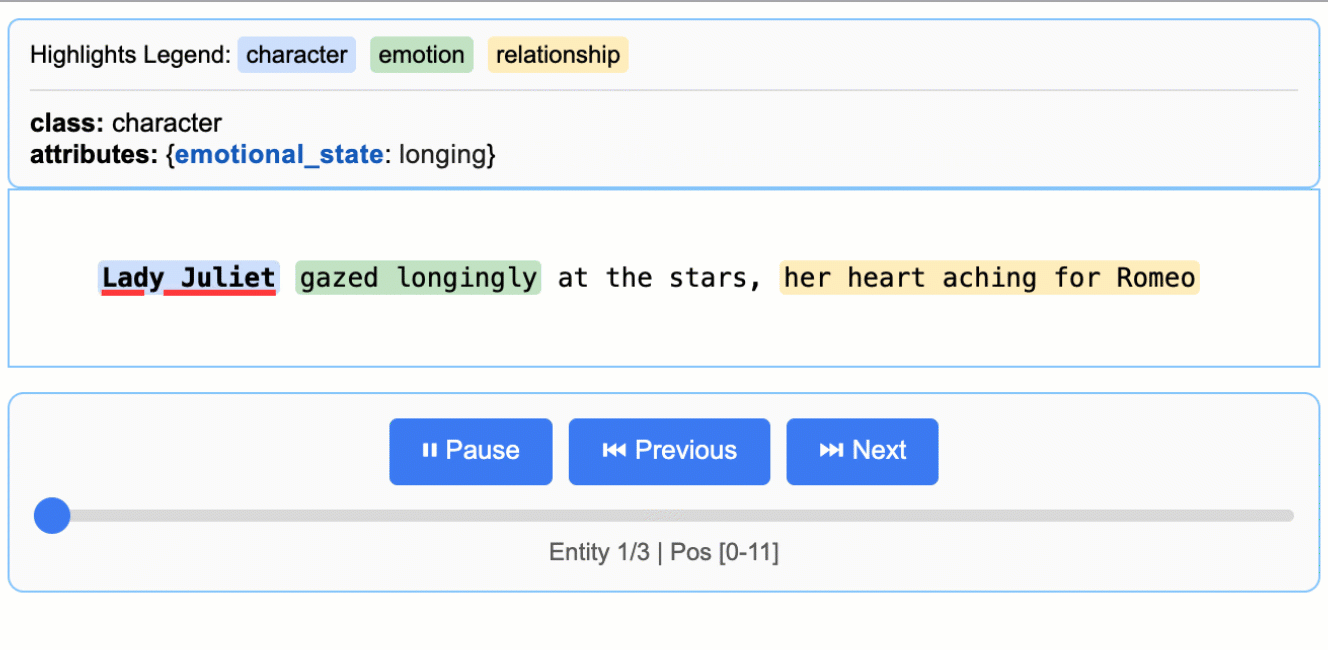
Source grounding is LangExtract’s ability to map every extraction back to its exact location in the original text at the character level. This enables visual highlighting, provenance tracking, and verification of extraction accuracy.
Why it matters: Source grounding transforms extractions from isolated data points into traceable, verifiable evidence anchored in the source document.
Every extraction includes a char_interval that specifies:
start_pos: Character position where the extraction begins (inclusive)
end_pos: Character position where the extraction ends (exclusive)
result = lx.extract( text_or_documents="ROMEO. But soft! What light through yonder window breaks?", prompt_description=prompt, examples=examples,)for extraction in result.extractions: print(f"Text: {extraction.extraction_text}") print(f"Position: {extraction.char_interval.start_pos}-{extraction.char_interval.end_pos}") print(f"Verified: {result.text[extraction.char_interval.start_pos:extraction.char_interval.end_pos]}")
Output:
Text: ROMEOPosition: 0-5Verified: ROMEOText: But soft!Position: 7-16Verified: But soft!
The resolver aligns extracted text to source positions using the WordAligner:
# From annotation.py:417-424aligned_extractions = resolver.align( resolved_extractions, text_chunk.chunk_text, token_offset, # Offset for chunked documents char_offset, # Character offset in original text tokenizer_inst=tokenizer,)
Extractions without valid alignment have None character intervals:
for extraction in result.extractions: if extraction.char_interval is None: print(f"Failed to align: {extraction.extraction_text}") else: print(f"Aligned: {extraction.extraction_text} at {extraction.char_interval}")
def verify_extractions(annotated_doc): """Check that all extractions match their source positions.""" for extraction in annotated_doc.extractions: if extraction.char_interval is None: print(f"Warning: No position for {extraction.extraction_text}") continue source_text = annotated_doc.text[ extraction.char_interval.start_pos: extraction.char_interval.end_pos ] if source_text != extraction.extraction_text: print(f"Mismatch: '{extraction.extraction_text}' vs '{source_text}'") return False return True
# Find extractions that span multiple sentencesfor extraction in result.extractions: span_text = result.text[ extraction.char_interval.start_pos: extraction.char_interval.end_pos ] if '.' in span_text or '\n' in span_text: print(f"Cross-boundary extraction: {extraction.extraction_text}")