Similarity-based RAG based on Vector-DB has shown big limitations in recent AI applications. Reasoning-based or agentic retrieval has become important in current developments. However, unlike classic RAG pipeline with embedding input, top-K chunks returns, and re-rank, what should an agentic-native retrieval API look like?For an agentic-native retrieval system, we need the ability to prompt for retrieval just as naturally as you interact with ChatGPT. Below, we provide an example of how the PageIndex Chat API enables this style of prompt-driven retrieval.
PageIndex Chat is an AI assistant that allows you to chat with multiple super-long documents without worrying about limited context or context rot problems. It is based on PageIndex, a vectorless reasoning-based RAG framework which gives more transparent and reliable results like a human expert.You can now access PageIndex Chat with API or SDK.
from pageindex import PageIndexClient# Get your PageIndex API key from https://dash.pageindex.ai/api-keysPAGEINDEX_API_KEY = "YOUR_PAGEINDEX_API_KEY"pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)
from pprint import pprintdoc_info = pi_client.get_document(doc_id)pprint(doc_info)if doc_info['status'] == 'completed': print(f"\n Document ready! ({doc_info['pageNum']} pages)")elif doc_info['status'] == 'processing': print("\n Document is still processing. Please wait and check again.")
Output:
{'createdAt': '2025-11-16T08:36:41.177000', 'description': 'This survey provides a comprehensive overview and taxonomy of ' 'Context Engineering for Large Language Models, covering ' 'foundational components, system implementations, evaluation ' 'methods, and future research directions.', 'id': 'pi-cmi1gp1hg01t20do2l3bgzwz1', 'name': '2507.13334_19.pdf', 'pageNum': 166, 'status': 'completed'} Document ready! (166 pages)
query = "What are the evaluation methods used in this paper?"for chunk in pi_client.chat_completions( messages=[{"role": "user", "content": query}], doc_id=doc_id, stream=True): print(chunk, end='', flush=True)
Sample Output:
I'll help you find the evaluation methods used in this paper. Let me start by examining the document structure to locate the relevant sections.Perfect! I can see there's a dedicated section on "Evaluation" (node_id: 0015) that covers pages 45-50. Let me extract the content from those pages to get detailed information about the evaluation methods.Based on the comprehensive evaluation section of the paper, here are the **evaluation methods** used:## Evaluation Framework OverviewThe paper presents a comprehensive evaluation framework organized into **Component-Level Assessment** and **System-Level Integration Assessment**.### 1. Component-Level Assessment (Intrinsic Evaluation)#### Prompt Engineering Evaluation:- **Semantic similarity metrics**- **Response quality assessment**- **Robustness testing** across diverse input variations- **Contextual calibration** assessment#### Long Context Processing Evaluation:- **"Needle in a haystack"** evaluation paradigm- **Multi-document reasoning tasks**- **Position interpolation techniques** evaluation- **Information retention, positional bias, and reasoning coherence** metrics[...continues with detailed evaluation methods...]
You can easily prompt the PageIndex Chat API to be a retrieval assistant:
retrieval_prompt = f"""Your job is to retrieve the raw relevant content from the document based on the user's query.Query: {query}Return in JSON format with an array of objects containing "page" (number) and "content" (string) fields."""full_response = ""for chunk in pi_client.chat_completions( messages=[{{"role": "user", "content": retrieval_prompt}}], doc_id=doc_id, stream=True): print(chunk, end='', flush=True) full_response += chunk
Sample Output:
I'll help you find the evaluation methods discussed in this paper. Let me start by examining the document structure to locate relevant sections.Now I can see the document structure. Section 6 is dedicated to "Evaluation" and spans pages 45-50. Let me retrieve the content from those pages to get the detailed evaluation methods.Perfect! I have retrieved the comprehensive evaluation section. Now let me compile the evaluation methods in the requested JSON format.```json[ { "page": 45, "content": "## 6. Evaluation\n\nThe evaluation of context-engineered systems presents unprecedented challenges that transcend traditional language model assessment paradigms. These systems exhibit complex, multi-component architectures with dynamic, context-dependent behaviors requiring comprehensive evaluation frameworks..." }, { "page": 46, "content": "Long context processing evaluation requires specialized metrics addressing information retention, positional bias, and reasoning coherence across extended sequences. The 'needle in a haystack' evaluation paradigm tests models' ability to retrieve specific information..." }, ...]
### Extract the JSON ResultsParse the JSON response to extract structured retrieval results:```pythonimport jsonimport re# Extract JSON from the responsejson_match = re.search(r'```json\n(.*?)\n```', full_response, re.DOTALL)if json_match: json_str = json_match.group(1) retrieved_data = json.loads(json_str) from pprint import pprint pprint(retrieved_data)
Output:
[{'content': '## 6. Evaluation\n' '\n' 'The evaluation of context-engineered systems presents ' 'unprecedented challenges that transcend traditional language ' 'model assessment paradigms...', 'page': 45}, {'content': 'Long context processing evaluation requires specialized metrics ' 'addressing information retention, positional bias, and reasoning ' 'coherence across extended sequences...', 'page': 46}, ...]
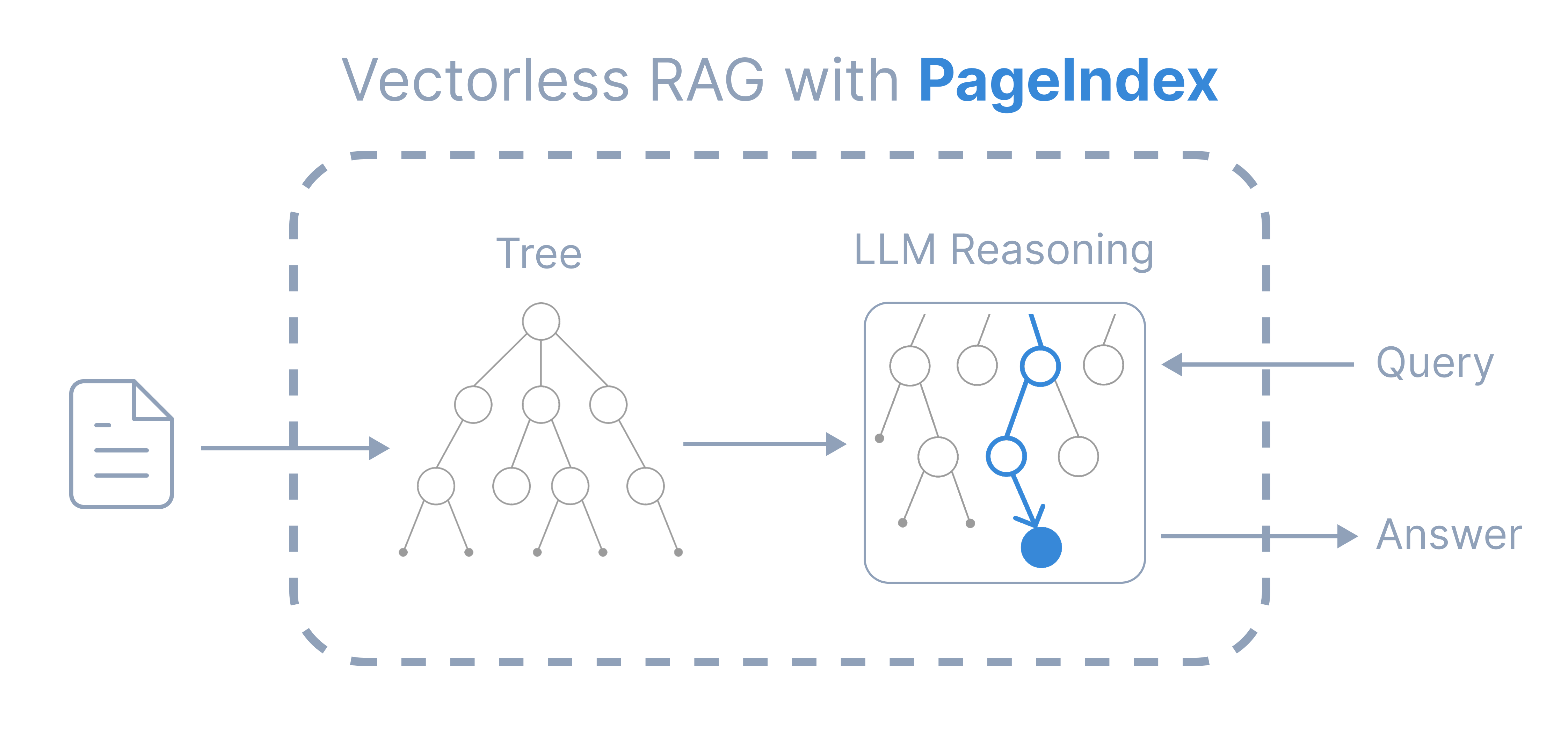 You can now access PageIndex Chat with API or SDK.
You can now access PageIndex Chat with API or SDK.