Documentation Index
Fetch the complete documentation index at: https://mintlify.com/vectifyai/pageindex/llms.txt
Use this file to discover all available pages before exploring further.

Introduction
PageIndex is a new reasoning-based, vectorless RAG framework that performs retrieval in two steps:
- Generate a tree structure index of documents
- Perform reasoning-based retrieval through tree search
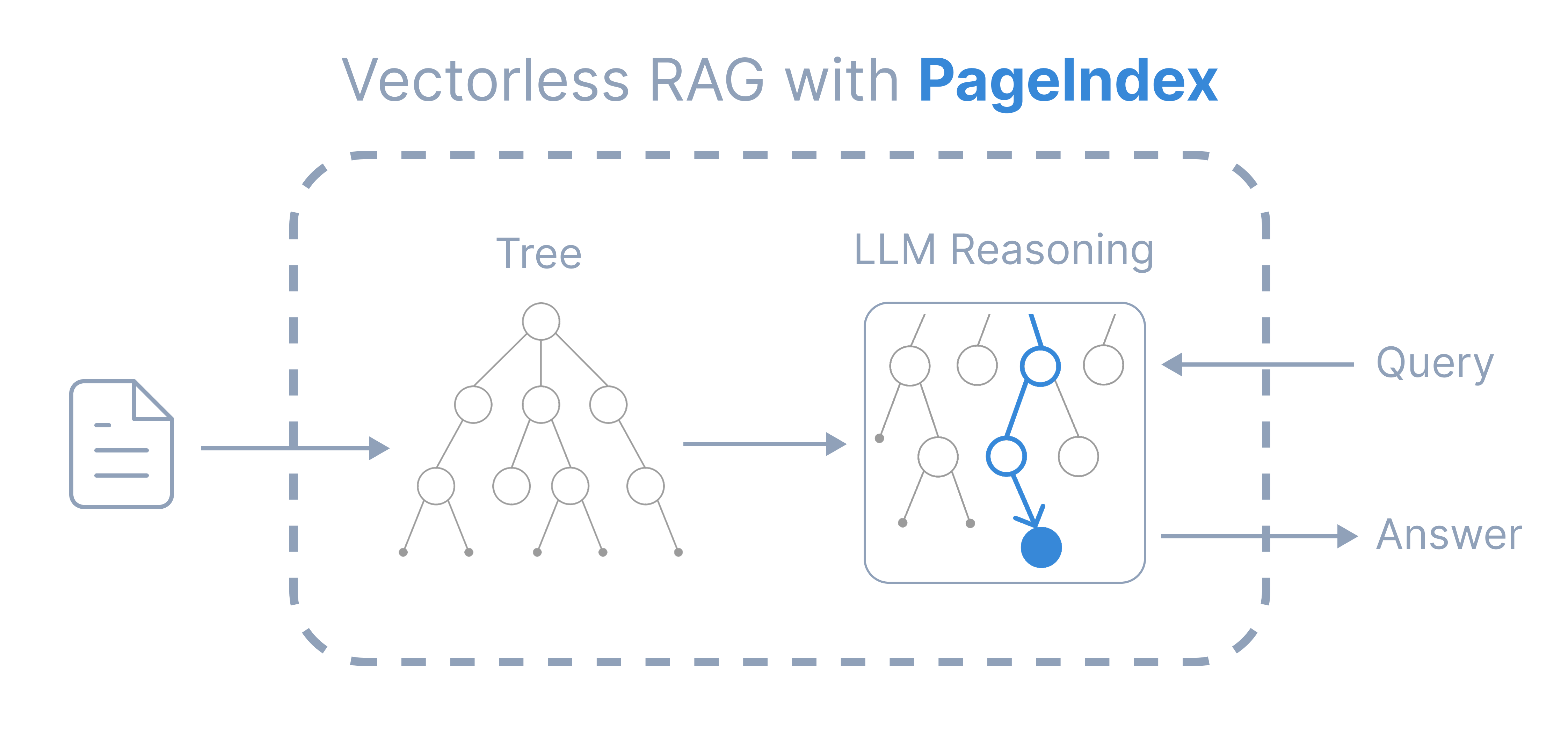 Compared to traditional vector-based RAG, PageIndex features:
Compared to traditional vector-based RAG, PageIndex features:
- No Vectors Needed: Uses document structure and LLM reasoning for retrieval
- No Chunking Needed: Documents are organized into natural sections rather than artificial chunks
- Human-like Retrieval: Simulates how human experts navigate and extract knowledge from complex documents
- Transparent Retrieval Process: Retrieval based on reasoning — say goodbye to approximate semantic search (“vibe retrieval”)
What You’ll Learn
This cookbook demonstrates a simple, minimal example of vectorless RAG with PageIndex. You will learn how to:
- Build a PageIndex tree structure of a document
- Perform reasoning-based retrieval with tree search
- Generate answers based on the retrieved context
This is a minimal example to illustrate PageIndex’s core philosophy and idea, not its full capabilities. More advanced examples are coming soon.
Setup
Install PageIndex
Install the PageIndex SDK:pip install --upgrade pageindex
Setup PageIndex Client
Initialize the PageIndex client with your API key:from pageindex import PageIndexClient
import pageindex.utils as utils
# Get your PageIndex API key from https://dash.pageindex.ai/api-keys
PAGEINDEX_API_KEY = "YOUR_PAGEINDEX_API_KEY"
pi_client = PageIndexClient(api_key=PAGEINDEX_API_KEY)
Setup LLM
Choose your preferred LLM for reasoning-based retrieval. In this example, we use OpenAI’s GPT-4.1:import openai
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"
async def call_llm(prompt, model="gpt-4.1", temperature=0):
client = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)
response = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content.strip()
Step 1: PageIndex Tree Generation
Submit a Document
Submit a document to generate its PageIndex tree structure:
import os, requests
pdf_url = "https://arxiv.org/pdf/2501.12948.pdf"
pdf_path = os.path.join("../data", pdf_url.split('/')[-1])
os.makedirs(os.path.dirname(pdf_path), exist_ok=True)
response = requests.get(pdf_url)
with open(pdf_path, "wb") as f:
f.write(response.content)
print(f"Downloaded {pdf_url}")
doc_id = pi_client.submit_document(pdf_path)["doc_id"]
print('Document Submitted:', doc_id)
Downloaded https://arxiv.org/pdf/2501.12948.pdf
Document Submitted: pi-cmeseq08w00vt0bo3u6tr244g
Get the Tree Structure
Retrieve the generated tree structure:
if pi_client.is_retrieval_ready(doc_id):
tree = pi_client.get_tree(doc_id, node_summary=True)['result']
print('Simplified Tree Structure of the Document:')
utils.print_tree(tree)
else:
print("Processing document, please try again later...")
[{'title': 'DeepSeek-R1: Incentivizing Reasoning Cap...',
'node_id': '0000',
'prefix_summary': '# DeepSeek-R1: Incentivizing Reasoning C...',
'nodes': [{'title': 'Abstract',
'node_id': '0001',
'summary': 'The partial document introduces two reas...'},
{'title': '1. Introduction',
'node_id': '0003',
'prefix_summary': 'The partial document introduces recent a...',
'nodes': [{'title': '1.1. Contributions',
'node_id': '0004',
'summary': 'This partial document outlines the main ...'}]},
...]}
]
Step 2: Reasoning-Based Retrieval
Use LLM for tree search to identify nodes that might contain relevant context:
import json
query = "What are the conclusions in this document?"
tree_without_text = utils.remove_fields(tree.copy(), fields=['text'])
search_prompt = f"""
You are given a question and a tree structure of a document.
Each node contains a node id, node title, and a corresponding summary.
Your task is to find all nodes that are likely to contain the answer to the question.
Question: {query}
Document tree structure:
{json.dumps(tree_without_text, indent=2)}
Please reply in the following JSON format:
{{
"thinking": "<Your thinking process on which nodes are relevant to the question>",
"node_list": ["node_id_1", "node_id_2", ..., "node_id_n"]
}}
Directly return the final JSON structure. Do not output anything else.
"""
tree_search_result = await call_llm(search_prompt)
View Reasoning Process
Print the retrieved nodes and reasoning:
node_map = utils.create_node_mapping(tree)
tree_search_result_json = json.loads(tree_search_result)
print('Reasoning Process:')
utils.print_wrapped(tree_search_result_json['thinking'])
print('\nRetrieved Nodes:')
for node_id in tree_search_result_json["node_list"]:
node = node_map[node_id]
print(f"Node ID: {node['node_id']}\t Page: {node['page_index']}\t Title: {node['title']}")
Reasoning Process:
The question asks for the conclusions in the document. Typically, conclusions are found in sections
explicitly titled 'Conclusion' or in sections summarizing the findings and implications of the work.
In this document tree, node 0019 ('5. Conclusion, Limitations, and Future Work') is the most
directly relevant...
Retrieved Nodes:
Node ID: 0019 Page: 16 Title: 5. Conclusion, Limitations, and Future Work
Step 3: Answer Generation
Extract relevant content from retrieved nodes:
node_list = json.loads(tree_search_result)["node_list"]
relevant_content = "\n\n".join(node_map[node_id]["text"] for node_id in node_list)
print('Retrieved Context:\n')
utils.print_wrapped(relevant_content[:1000] + '...')
Generate Answer
Generate an answer based on the retrieved context:
answer_prompt = f"""
Answer the question based on the context:
Question: {query}
Context: {relevant_content}
Provide a clear, concise answer based only on the context provided.
"""
print('Generated Answer:\n')
answer = await call_llm(answer_prompt)
utils.print_wrapped(answer)
Generated Answer:
The conclusions in this document are:
- DeepSeek-R1-Zero, a pure reinforcement learning (RL) approach without cold-start data, achieves
strong performance across various tasks.
- DeepSeek-R1, which combines cold-start data with iterative RL fine-tuning, is more powerful and
achieves performance comparable to OpenAI-o1-1217 on a range of tasks.
- Distilling DeepSeek-R1's reasoning capabilities into smaller dense models is promising; for
example, DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks...
What’s Next
This cookbook has demonstrated a basic, minimal example of reasoning-based, vectorless RAG with PageIndex. The workflow illustrates the core idea:
Generating a hierarchical tree structure from a document, reasoning over that tree structure, and extracting relevant context, without relying on a vector database or top-k similarity search.
While this cookbook highlights a minimal workflow, the PageIndex framework is built to support far more advanced use cases. In upcoming tutorials, we will introduce:
- Multi-Node Reasoning with Content Extraction — Scale tree search to extract and select relevant content from multiple nodes
- Multi-Document Search — Enable reasoning-based navigation across large document collections, extending beyond a single file
- Efficient Tree Search — Improve tree search efficiency for long documents with a large number of nodes
- Expert Knowledge Integration and Preference Alignment — Incorporate user preferences or expert insights by adding knowledge directly into the LLM tree search, without the need for fine-tuning
Learn More