Documentation Index
Fetch the complete documentation index at: https://mintlify.com/JagravNaik/bedrock-chat/llms.txt
Use this file to discover all available pages before exploring further.
Architecture Overview
Bedrock Chat is built on a serverless, fully managed AWS architecture that eliminates infrastructure management while providing scalability, reliability, and security. All AI model interactions happen through Amazon Bedrock within your AWS account—no data leaves AWS.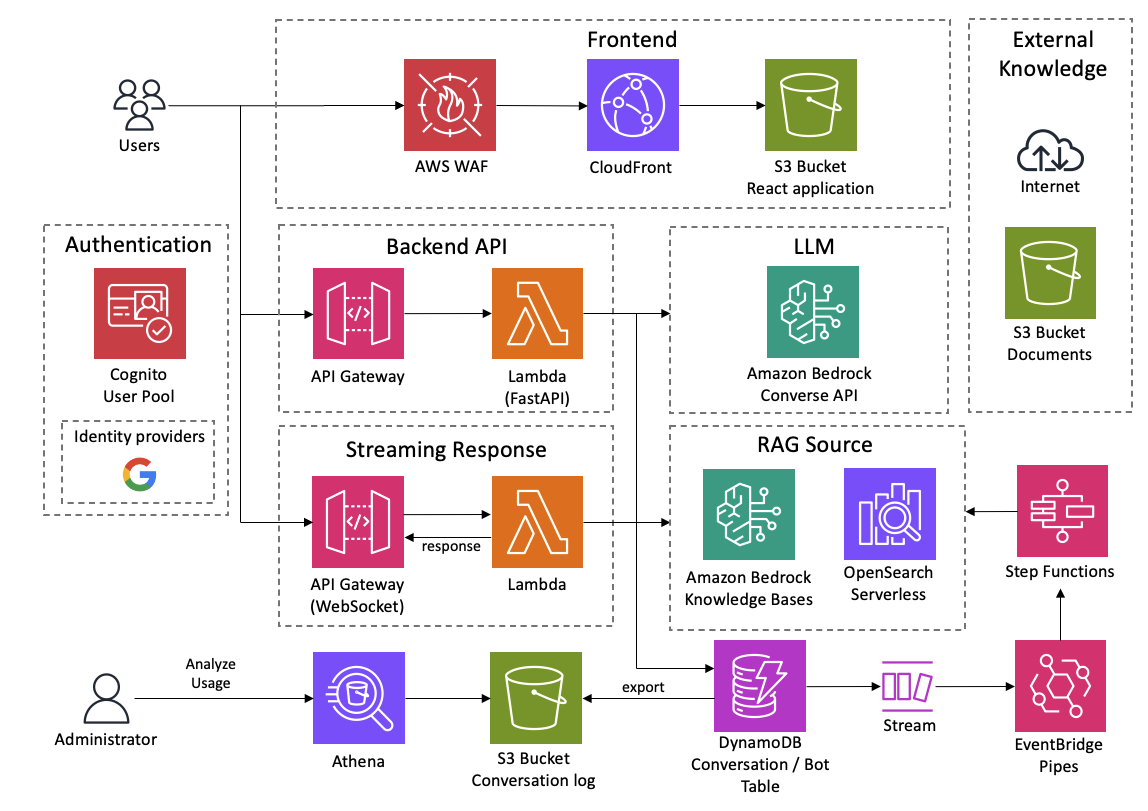
Core AWS Services
Bedrock Chat leverages the following AWS managed services:Frontend Layer
Amazon CloudFront
Amazon CloudFront
Purpose: Global content delivery network (CDN) for the frontend applicationFeatures:
- Automatic HTTPS encryption
- Global edge locations for low latency
- Custom domain support with Route 53
- Geo-restriction capabilities
- IPv6 support (configurable)
Amazon S3
Amazon S3
Purpose: Static asset storage and document hostingBuckets:
- Frontend bucket: Stores compiled React application (Vite build output)
- Document bucket: Stores uploaded documents for knowledge bases
- Access logs bucket: Stores CloudFront and S3 access logs
- Large message bucket: Stores oversized WebSocket messages
- Source bucket: Stores CDK source code for CodeBuild
AWS WAF
AWS WAF
Purpose: Web Application Firewall for traffic filteringWebACLs:
- Frontend WAF: Protects CloudFront distribution (us-east-1)
- Cognito WAF: Protects Cognito endpoints (regional)
- Published API WAF: Protects published bot APIs (regional)
- IP allowlist/denylist (IPv4/IPv6)
- Geographic restrictions (country-based)
- Rate limiting
- Common web exploits protection
Authentication & Authorization
Amazon Cognito
Amazon Cognito
Purpose: User authentication and authorizationComponents:
- User Pool: Manages user identities, registration, and sign-in
- User Pool Client: Configures authentication flows
- User Groups:
Admin- Administrative accessCreatingBotAllowed- Can create custom botsPublishAllowed- Can publish bot APIs
- Self-registration (configurable)
- Email domain restrictions
- External identity providers (Google, OIDC)
- MFA support
- Token-based authentication with configurable expiration
Backend API Layer
Amazon API Gateway
Amazon API Gateway
Purpose: RESTful API endpoints for backend servicesAPIs:
- Backend API: Main REST API for application logic
- WebSocket API: Real-time streaming for chat responses
- Published APIs: Dynamically created APIs for published bots
- Cognito authorizer integration
- Request/response validation
- CORS configuration
- CloudWatch logging
- Throttling and quotas
AWS Lambda
AWS Lambda
Purpose: Serverless compute for API handlersFunctions:
- API Handler: FastAPI application via Lambda Web Adapter
- WebSocket Handler: Handles WebSocket connections and streaming
- Custom resource handlers: CDK custom resources
- Lambda SnapStart for Python (configurable)
- Provisioned concurrency for hot starts
- Environment variables for configuration
- VPC integration for OpenSearch access
- FastAPI for REST endpoints
- Boto3 for AWS SDK
- LangChain for agent orchestration
Data Layer
Amazon DynamoDB
Amazon DynamoDB
Purpose: NoSQL database for application dataTables:
- Conversation Table: Stores chat conversations and messages
- Bot Table: Stores custom bot configurations and metadata
- Export Table: Staging table for analytics exports
- On-demand capacity mode (auto-scaling)
- Point-in-time recovery (PITR) enabled
- DynamoDB Streams for event processing
- Single-table design with composite keys
Amazon OpenSearch Serverless
Amazon OpenSearch Serverless
Purpose: Vector database and full-text search for knowledge basesCollections:
- Knowledge Base Collections: Per-bot or multi-tenant collections for RAG
- Bot Store Collection: Search and discovery for bot marketplace
- Vector search with k-NN
- Full-text search with BM25
- Automatic scaling (OCU-based)
- Data access policies (IAM-based)
- Optional standby replicas for high availability
- Multi-tenant mode shares collections across bots
- Configurable replicas (
enableRagReplicas,enableBotStoreReplicas) - Starts at 0.5 OCU for small workloads
AI & Machine Learning
Amazon Bedrock
Amazon Bedrock
Purpose: Managed foundation models APISupported Models:
- Claude: v4-opus, v4.5-opus, v3.7-sonnet, v3.5-sonnet, v3.5-haiku
- Amazon Nova: nova-pro, nova-lite, nova-micro
- Llama: llama3-3-70b-instruct, llama3-2-90b-instruct
- Mistral: mistral-large-2, mixtral-8x7b-instruct
- DeepSeek: deepseek-r1
- Streaming responses
- Cross-region inference (configurable)
- Global inference profiles
- Usage metrics and logging
- Model access controls per region
bedrock-runtime client with converse API.Amazon Bedrock Knowledge Bases
Amazon Bedrock Knowledge Bases
Purpose: Managed RAG (Retrieval-Augmented Generation) serviceComponents:
- Data Source: S3 bucket with document ingestion
- Embedding Model: Amazon Titan Embeddings
- Vector Store: OpenSearch Serverless
- Ingestion Pipeline: Step Functions orchestration
- Automatic document parsing (PDF, TXT, HTML, DOCX, etc.)
- Chunking and embedding
- Metadata filtering (multi-tenant support)
- Synchronization jobs
- Import existing Knowledge Bases
Orchestration & Automation
AWS Step Functions
AWS Step Functions
Purpose: Orchestrate multi-step workflowsState Machines:
- Embedding State Machine: Orchestrates document ingestion pipeline
- Trigger Knowledge Base sync
- Monitor sync status
- Update DynamoDB with completion status
- Handle failures and retries
Amazon EventBridge Pipes
Amazon EventBridge Pipes
Purpose: Event-driven automationPipes:
- Bot Deletion Pipe:
- Source: DynamoDB Streams (Bot Table)
- Filter: Deletion events
- Target: Lambda to delete CloudFormation stack
AWS CodeBuild
AWS CodeBuild
Purpose: CI/CD for dynamic infrastructureProjects:
- API Publish CodeBuild: Creates CloudFormation stacks for published bot APIs
- Bedrock Custom Bot CodeBuild: Creates CloudFormation stacks for bot Knowledge Bases
- Bedrock Shared KB CodeBuild: Creates shared multi-tenant Knowledge Base stacks
- Lambda triggers CodeBuild with parameters
- CodeBuild synthesizes CDK stack
- CDK deploys CloudFormation stack
- Outputs returned to Lambda
Analytics & Monitoring
Amazon Athena
Amazon Athena
Purpose: SQL query service for analyticsData Sources:
- DynamoDB exports to S3 (via PITR)
- CloudFront access logs
- API Gateway logs
- Bot usage statistics
- Conversation analytics
- User activity metrics
- Cost analysis
AWS Glue
AWS Glue
Purpose: Data catalog and ETLComponents:
- Glue Database: Metadata catalog for DynamoDB exports
- Glue Tables: Schema definitions for analytics queries
- Glue Crawlers: (Optional) Discover new data partitions
Amazon CloudWatch
Amazon CloudWatch
Purpose: Monitoring, logging, and alarmsLogs:
- Lambda function logs
- API Gateway access logs
- CodeBuild build logs
- Step Functions execution logs
- Lambda invocations, duration, errors
- API Gateway requests, latency
- DynamoDB read/write units
- OpenSearch OCU usage
Architecture Patterns
Serverless Architecture
Zero Infrastructure Management
All components are fully managed AWS services:
- No EC2 instances to patch or maintain
- Automatic scaling based on demand
- Pay-per-use pricing model
- Built-in high availability
Event-Driven Design
EventBridge Pipes react to DynamoDB changes to trigger cleanup workflows.Infrastructure as Code
All infrastructure is defined using AWS CDK (TypeScript):- Version control for infrastructure
- Repeatable deployments
- Multi-environment support (
parameter.ts) - Type-safe configuration
Multi-Tenant Knowledge Bases
Metadata filtering isolates data while sharing infrastructure:Dynamic Stack Creation
CodeBuild creates nested CloudFormation stacks on-demand: Stacks:BrChatKbStack-{botId}: Knowledge Base per botApiPublishmentStack-{apiId}: Published bot APIBedrockSharedKbStack: Multi-tenant Knowledge Base
Security Architecture
Defense in Depth
Security Layers:- WAF: IP filtering, geo-restrictions, rate limiting
- HTTPS: TLS encryption in transit
- Cognito: User authentication and authorization
- IAM: Least-privilege service permissions
- Encryption: At-rest encryption for all storage services
IAM Roles & Policies
Lambda Execution Role
Lambda Execution Role
Permissions:
- DynamoDB read/write (specific tables)
- S3 read/write (specific buckets)
- Bedrock InvokeModel
- OpenSearch data access (via data access policies)
- CloudWatch Logs write
- Step Functions start execution
CodeBuild Service Role
CodeBuild Service Role
Permissions:
- CloudFormation create/update/delete stack
- IAM create/update role (scoped to specific paths)
- OpenSearch create collection
- Bedrock create Knowledge Base
- S3 read source bucket
DynamoDB Stream Role
DynamoDB Stream Role
Permissions:
- DynamoDB Streams read
- Lambda invoke (for EventBridge Pipes target)
Data Isolation
- Per-User Data: DynamoDB partition key includes user ID
- Per-Bot Data: OpenSearch metadata filtering by bot ID
- Cognito Groups: Control access to bot creation and publishing
- API Gateway Authorizer: Validates JWT tokens from Cognito
Scalability & Performance
Auto-Scaling Components
| Service | Scaling Method | Limits |
|---|---|---|
| Lambda | Concurrent executions | 1000 (default), request increase |
| DynamoDB | On-demand capacity | Unlimited |
| API Gateway | Automatic | 10,000 RPS (default) |
| OpenSearch | OCU-based | 2-100 OCU per collection |
| CloudFront | Global edge network | Unlimited |
Performance Optimizations
Lambda SnapStart
Reduces cold start times by 50-90% for Python functions
CloudFront Caching
Caches static assets at edge locations globally
DynamoDB Streams
Processes changes asynchronously for analytics
WebSocket Streaming
Real-time token-by-token response streaming
Cost Optimization
Cost Drivers
- Amazon Bedrock: Pay-per-token (input/output)
- OpenSearch Serverless: OCU-hours
- Lambda: Invocations + GB-seconds
- DynamoDB: Read/write capacity (on-demand)
- CloudFront: Data transfer out
Cost Reduction Strategies
High Availability
Regional Resilience
- Multi-AZ: All services (Lambda, DynamoDB, API Gateway) run across multiple Availability Zones
- OpenSearch Replicas: Optional standby replicas for Knowledge Bases
- CloudFront: Global edge network with automatic failover
- S3: 99.999999999% durability with cross-AZ replication
Disaster Recovery
- DynamoDB PITR: Point-in-time recovery within last 35 days
- S3 Versioning: Can be enabled for document buckets
- CloudFormation Stacks: IaC enables rapid redeployment
- Cross-Region: Deploy to multiple regions with separate stacks
Deployment Architecture
CloudShell Deployment Flow
CDK Deployment Flow
Tech Stack Summary
Frontend
- Framework: React 18
- Build Tool: Vite
- Styling: Tailwind CSS
- State Management: Zustand, XState
- Authentication: AWS Amplify
- API Client: Axios, SWR
- Markdown: React Markdown with syntax highlighting
Backend
- Runtime: Python 3.12
- Framework: FastAPI
- Adapter: AWS Lambda Web Adapter
- AWS SDK: Boto3
- Agent Framework: LangChain
- Database: DynamoDB (Boto3)
Infrastructure
- IaC: AWS CDK (TypeScript)
- Language: Node.js 20
- Package Manager: npm
- Testing: Jest
Next Steps
Deploy Bedrock Chat
Follow the quickstart guide to deploy the architecture
CDK Deep Dive
Learn about advanced CDK deployment options
Configuration
Configure architecture parameters and optimizations
Custom Development
Set up local development environment