Fine-tuning LFM2-350M for browser control using GRPO (Group Relative Policy Optimization) and OpenEnv.Documentation Index
Fetch the complete documentation index at: https://mintlify.com/Liquid4All/cookbook/llms.txt
Use this file to discover all available pages before exploring further.
What is browser control?
Browser control is the ability of a language model to navigate and interact with websites by generating sequences of actions (clicking elements, typing text, scrolling) to accomplish user-specified tasks like booking flights, filling forms, or extracting information from web pages. For example:- A Vision Language Model (VLM) can take as inputs a screenshot and the user goal, and generates a sequence of actions to accomplish that goal.
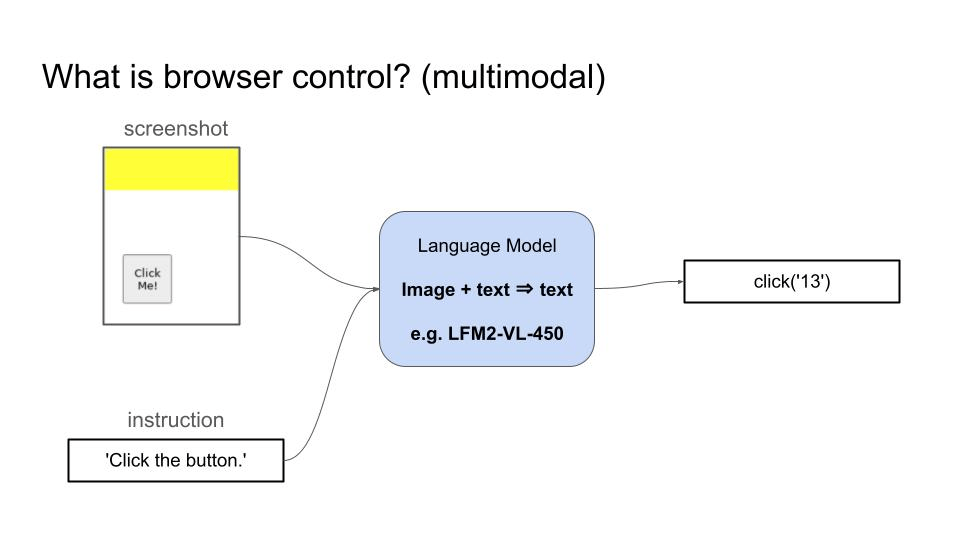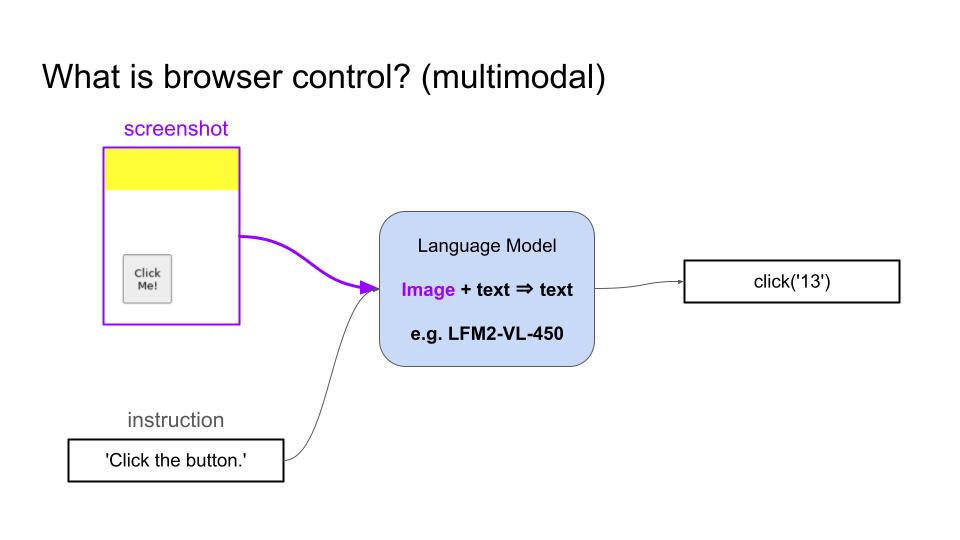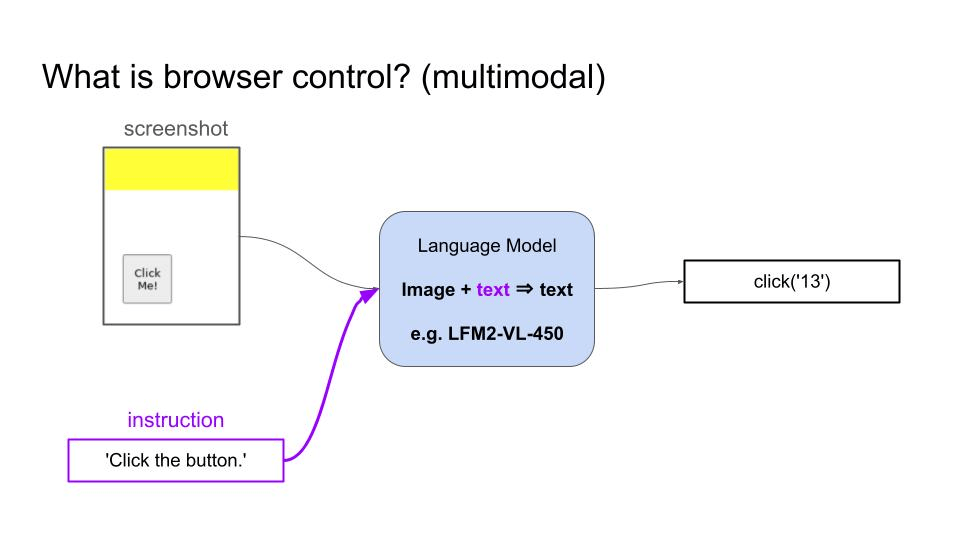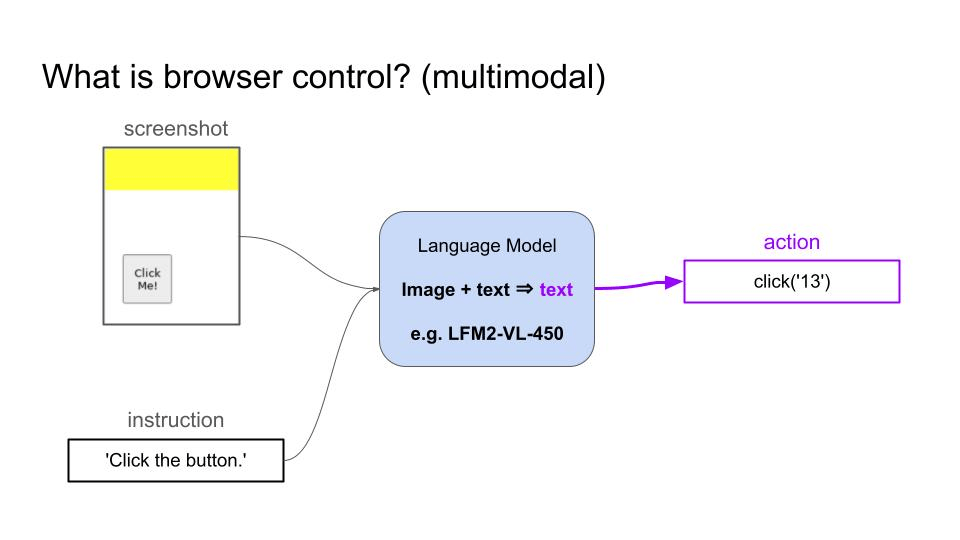
- A text-only Language Model can take as input the HTML code of the page and proceeds in the same way.
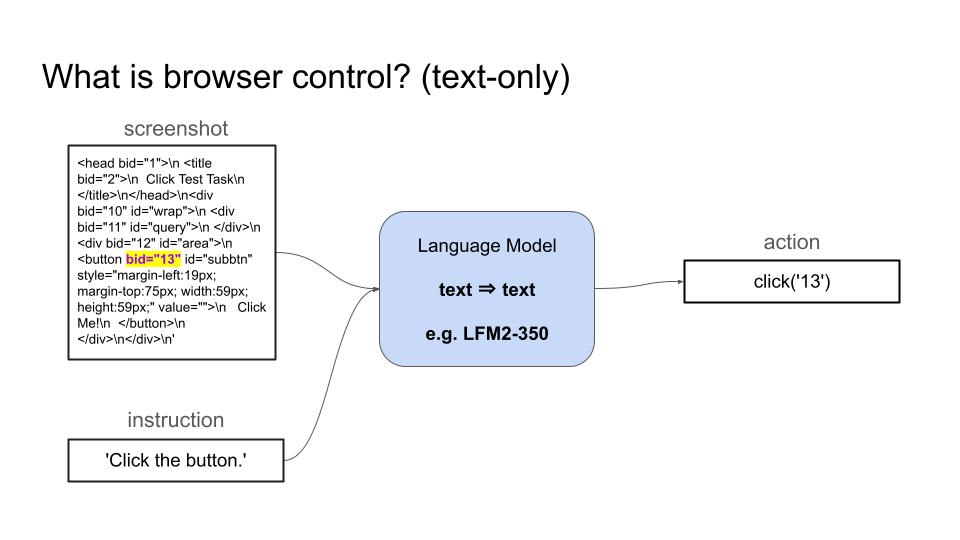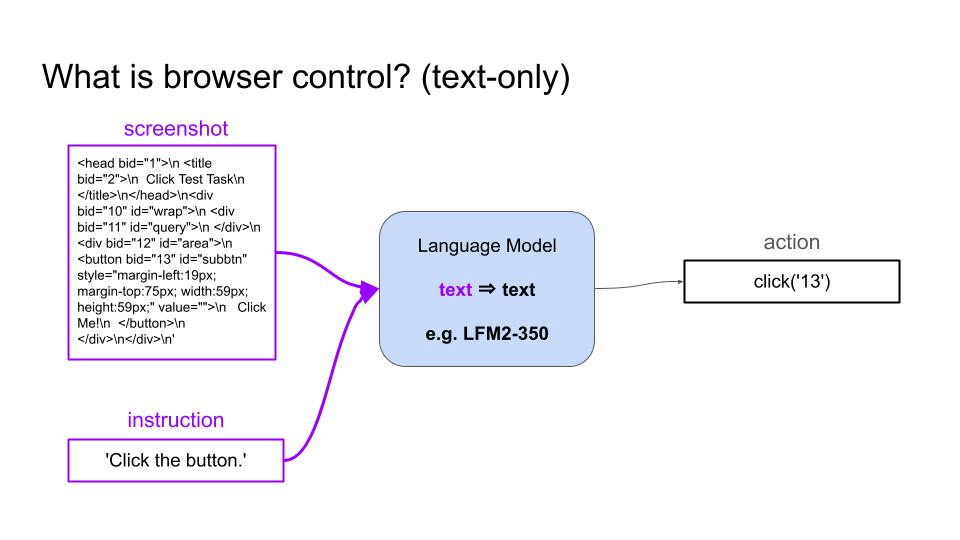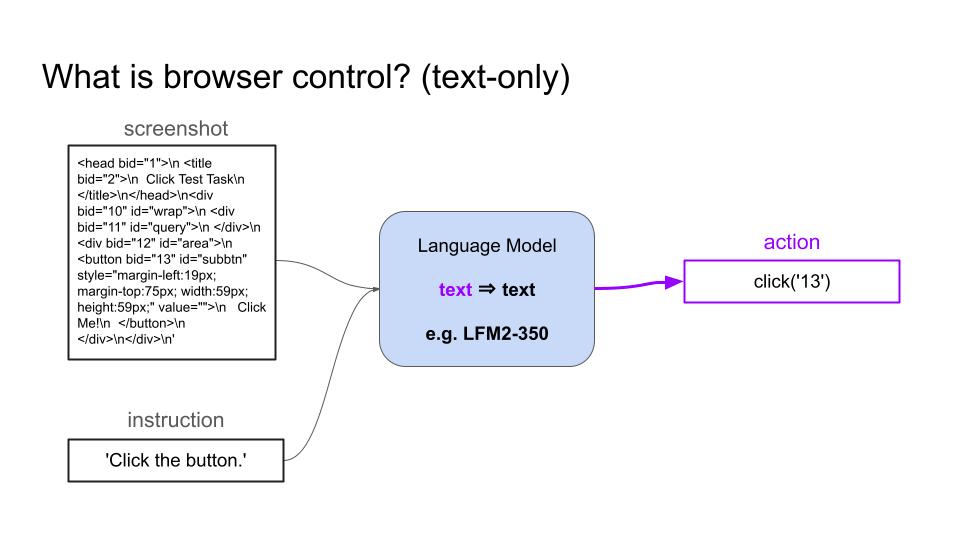
Real-world use cases
Browser control has many real-world applications including good ones like:- Accessibility assistance: A screen reader companion that navigates complex checkout flows, reads product descriptions, and completes purchases for visually impaired users on Amazon or grocery delivery sites
- Healthcare appointment management: An app that checks multiple clinic websites for appointment availability, books the earliest slot matching your insurance, and adds it to your calendar
- Bill payment automation: A monthly routine that visits utility company websites, verifies amounts, and schedules payments from your bank account
- Review manipulation: Bots that create fake accounts and post fraudulent reviews on Amazon, Yelp, or Google to artificially boost product ratings or damage competitors
Why do we need Reinforcement Learning (RL)?
In browser control, there are often multiple valid ways to accomplish a goal. Verifying if the Language Model has solved the task (RL with verifiable rewards) is way easier/cheaper/faster than collecting a sufficiently large and diverse set of (input, output) examples to do Supervised Fine Tuning.Example
Task: “book the shortest one-way flight from LAF to Akuton, AK on 12/06/2016”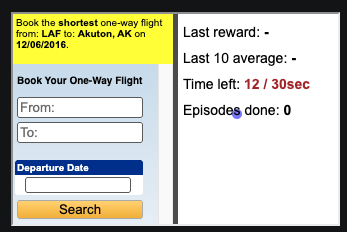
Building blocks of an RL training framework
The idea of RL is to iteratively let the Language Model (aka the policy):- Observe the state of the environment (e.g. DOM elements of the website)
- Output an action (aka text completion) and,
- Occasionally obtain a positive reward (aka feedback) from the environment
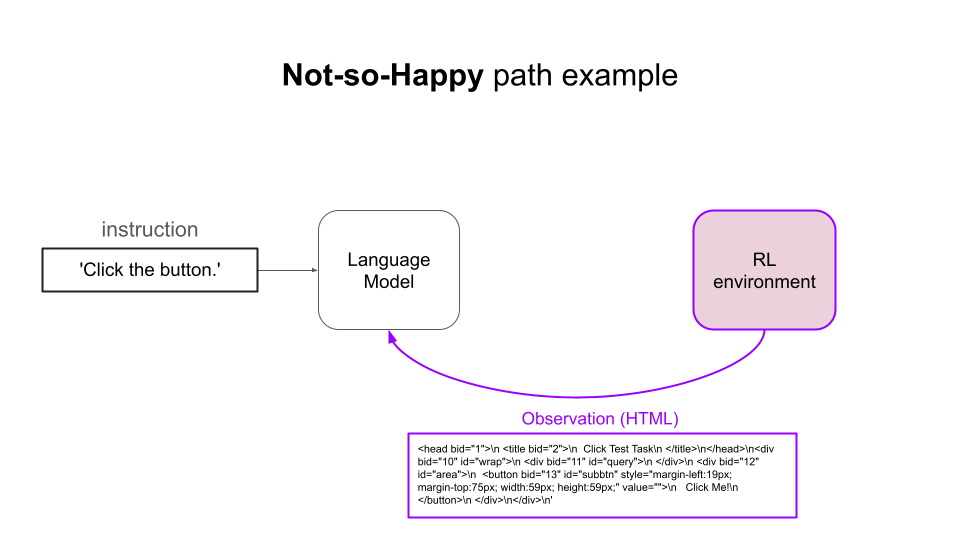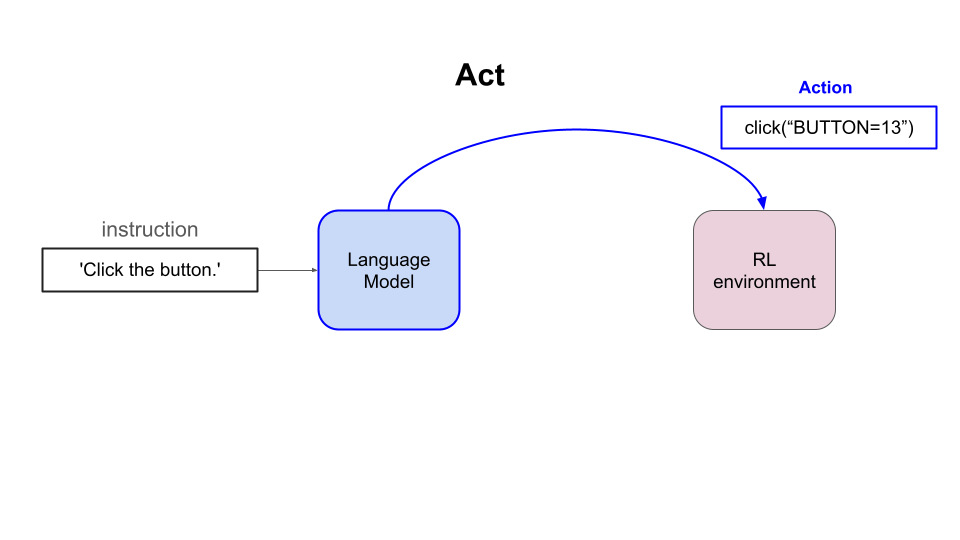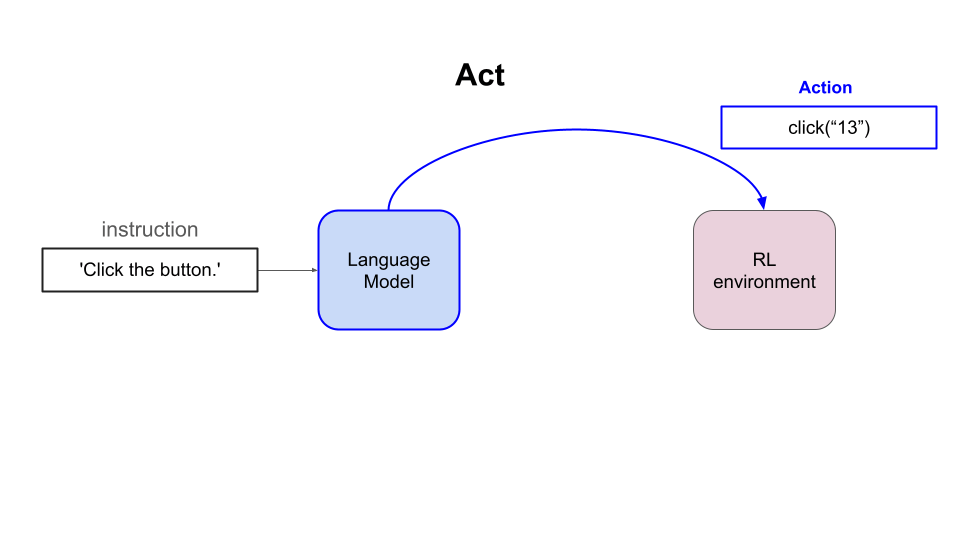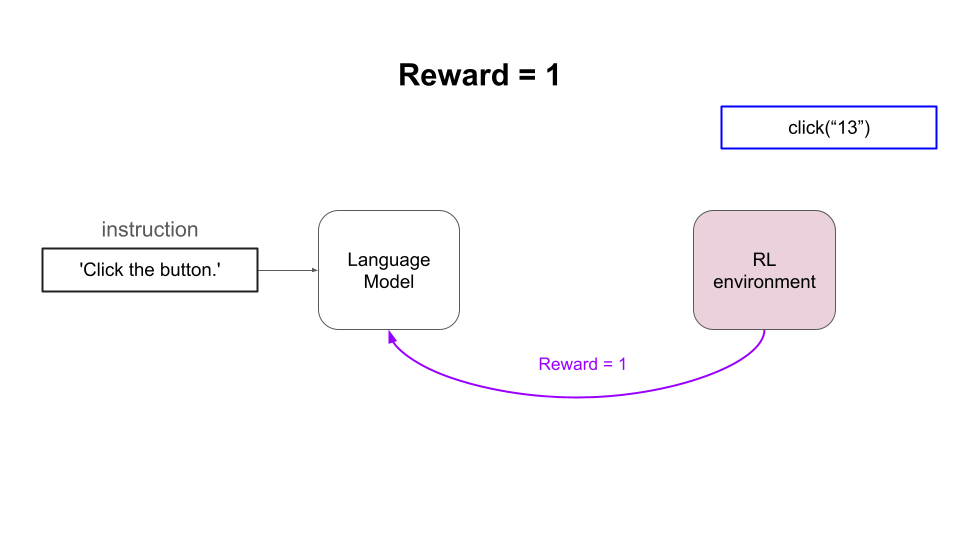
- Extract structure and content from the page Document Object Model (DOM)
- Check URLs to verify the agent landed on the desired page, or
- Query databases to check the agent modified their state correctly
1. The environment: BrowserGym via OpenEnv
OpenEnv is an open-source library that:- Standardizes Python access to a large collection of RL environments
- Simplifies deployment of RL environments as standalone Docker containers, that can run either locally, remotely on Kubernetes or as Hugging Face spaces
- Helps AI researchers generate and publish new RL environments
- Mini World of Bits++ (aka MiniWoB)
- WebArena
- VisualWebArena
- WorkArena
click-test, aka learning to click a button.

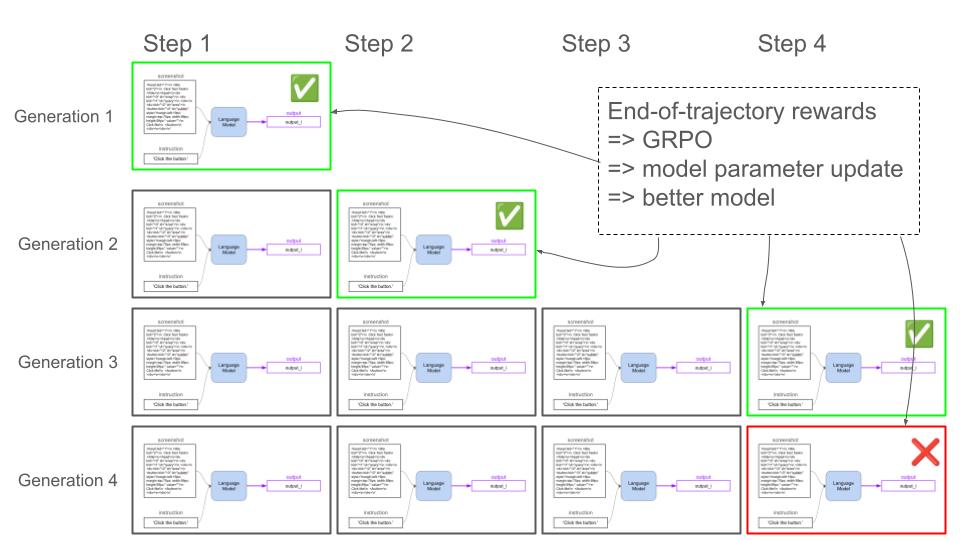
2. The RL algorithm: GRPO
As the Language Model interacts with the environment you collect a sequence of rollouts with sparse rewards from the environment. Using these sparse rewards the RL algorithm (e.g. GRPO) adjusts the Language Model parameters to increase the chances of getting larger rewards.
3. The policy: LFM2-350M
We will be using LFM2-350M, which is a small-yet-powerful-and-fast language model with:- Knowledge (MMLU, GPQA)
- Instruction following (IFEval, IFBench)
- Mathematical reasoning (GSM8K, MGSM)
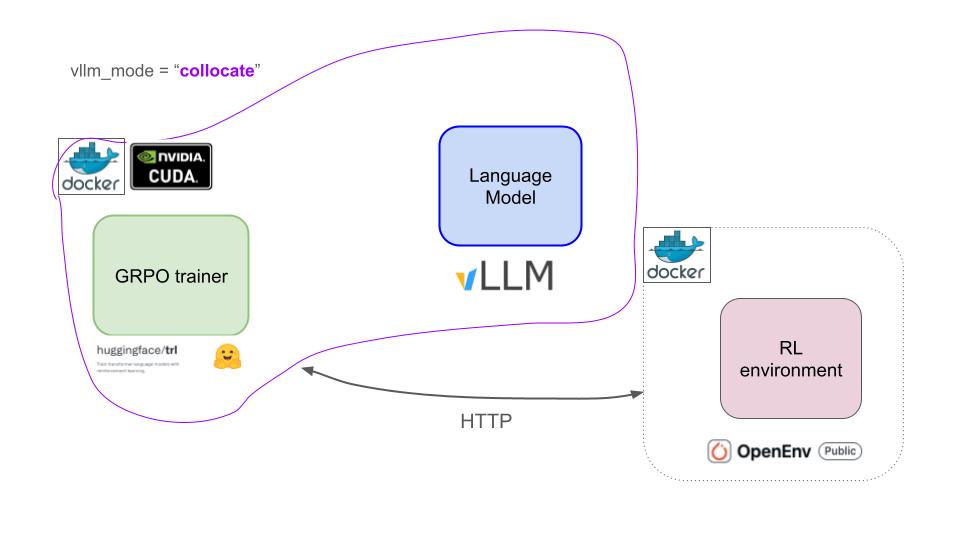
Architecture
The 3 components of our RL training framework are:- The
GRPOTrainerfrom the trl library that implements the GRPO algorithm. It needs to run on GPU so the backward pass that updates model parameters is fast enough. - The
vLLMserver to generate rollouts with LFM2-350M. It needs to run on GPU to parallelize the generation of rollouts. - The Docker container with the
BrowserGymenvironment, running as a Hugging Face space. Feel free to run locally or on your infra Kubernetes. This one can run on CPU.
Experiments
Full fine-tune
The first experiment we run is a full fine-tune of LFM2-350M:click-test task is an easy one, and the model is capable of solving it in less than 10 attempts from the beginning.
The final checkpoint is available on HF: Paulescu/LFM2-350M-browsergym-20251224-013119
Parameter efficient fine-tune with LoRA
With LoRA we can match full fine-tune results with way less compute and time:Next steps
- Run experiments for a more complex task like
book-flight