Use this file to discover all available pages before exploring further.
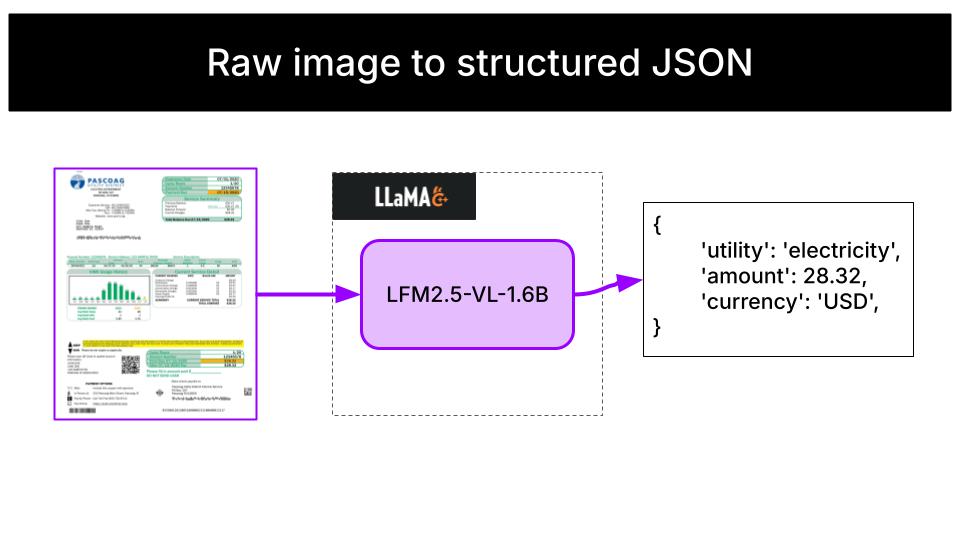
A Python CLI that extracts payment details from invoice PDFs. This is a practical example of building local AI tools with no cloud costs, no network latency, and no data privacy loss.
The tool supports two modes: watch (continuous monitoring) and process (one-shot).The tool automatically starts and stops llama-server for you — no need to run it separately.
The model works perfectly out-of-the-box on our sample of invoices. However, depending on your specific invoice formats and layouts, you may encounter cases where the extraction is not accurate enough.In those cases, you can fine-tune the model on your own dataset to improve accuracy. Check out the fine-tuning notebook for Vision Language Models to learn how.